
What is synthetic data?
Any information that has been created artificially is considered synthetic data. Synthetic data is utilized in machine-learning models for validation or training, simulating operational or production data. Synthetic data has a number of key advantages, including the ability to generate large training datasets without the need for manual labeling of data and the reduction of restrictions associated with the use of regulated or sensitive data.
Moreover, synthetic data can alleviate privacy concerns related to potentially sensitive data generated from the actual world while also reducing costs. In comparison to genuine data, which could not precisely reflect the complete spectrum of facts about the real world, it might help lessen bias. By including rare cases that represent realistic possibilities but may be challenging to source from authentic data, synthetic data can offer greater diversity.
Why is synthetic data helpful for early stage models?
You might be asking how does synthetic data help the training of early stage models. Well, the answer is simple: the data is critical when building a ML model. It does not matter which algorithm you use if it is not able to learn correctly from the data. Our end goal is to train a model that generalizes well for all possible classes and for this reason we need balanced data (i.e. where the number of samples belonging to each class is similar).
Classification problems are ubiquitous in machine-learning, but during the training of their early-stage models, an imbalance in the number of samples of each class leads to poor recognition of the minority class thus poor performance of the model because of a biased prediction. To solve bias, a well balanced dataset is important, however, is not always possible to obtain these equivalent class proportions from the real data and therefore measures have to be taken.
Let’s take imbalance within a binary classification dataset as an example where one of classes contains less numbers than the other. For example, if we only have 20-30% of a minority class we can use techniques of oversampling (a type of data augmentation) that make use of synthetic data to balance the data.
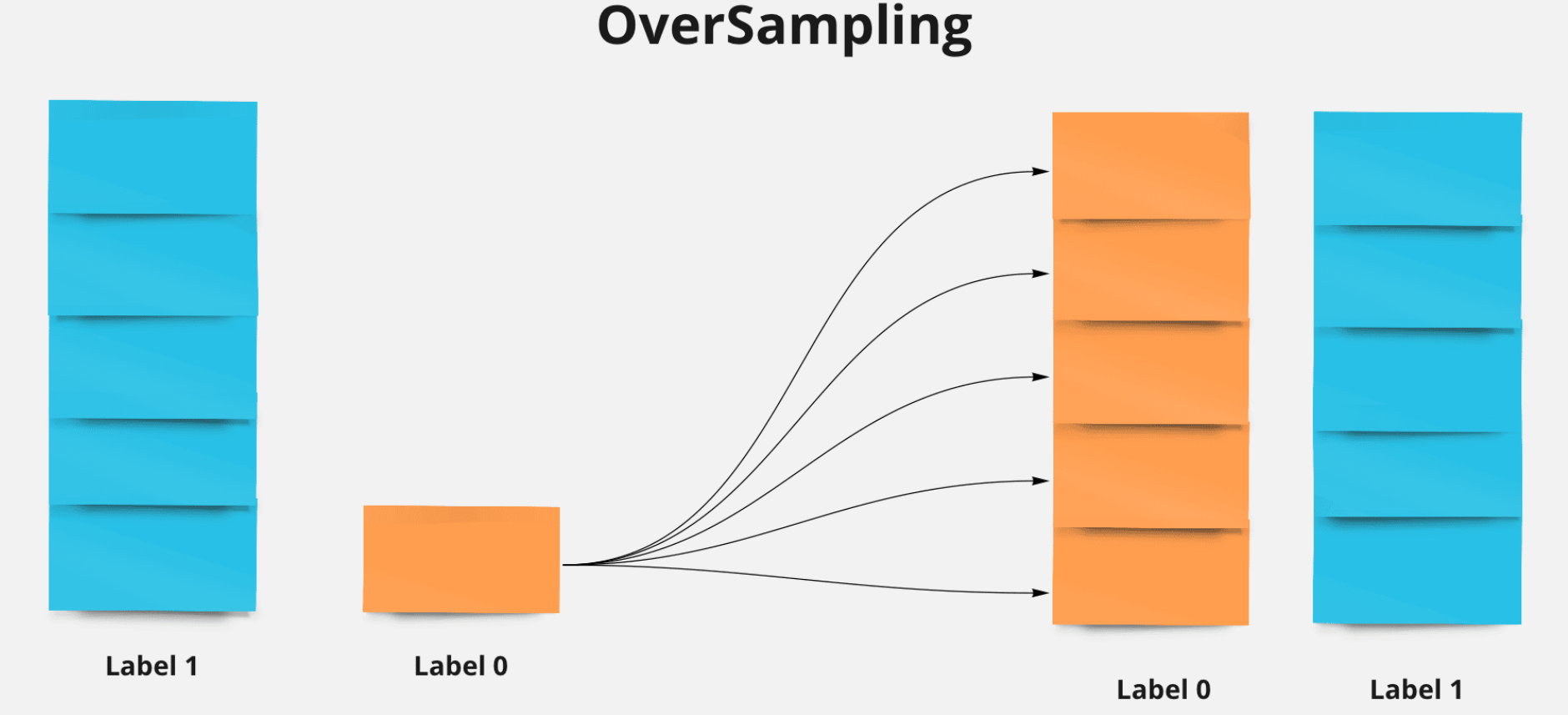
As you know machine learning needs a lot of data to be trained (some neural network use millions of samples) but thanks to the scalability of artificial data we can generate massive amounts of high quality, unbiased and cheap data. A big advantage is that the generation of data can be done easily by a data engineer/scientist in the desired format but, as bias is an ever-standing presence in society, it holds space in AI datasets as well. Because these datasets are created by humans, they could show the same biases as the people who create them. No, these aren’t massive, visible prejudices, but they’re sometimes sufficient to impact the learning process during the training of the model. For the dataset to be truly unbiased, it needs to cover every possible scenario.
We can even go further and create an entire synthetic dataset to train really complex models, as these datasets are adapted, by controlling the processes of data generation, to the degree of the use case difficulty that we face. If the synthetic generation function is well thought out, the resulting synthetic datasets can be much better than real-world datasets because the rare and crucial corner cases are labeled, then the ML models are able to meaningfully learn those corner cases and therefore to generalize better.
Generation Methods
In order to generate synthetic data there are a variety of algorithms that learn the data distribution and extrapolate to create higher quality data. Today we will only cover some basic ones.
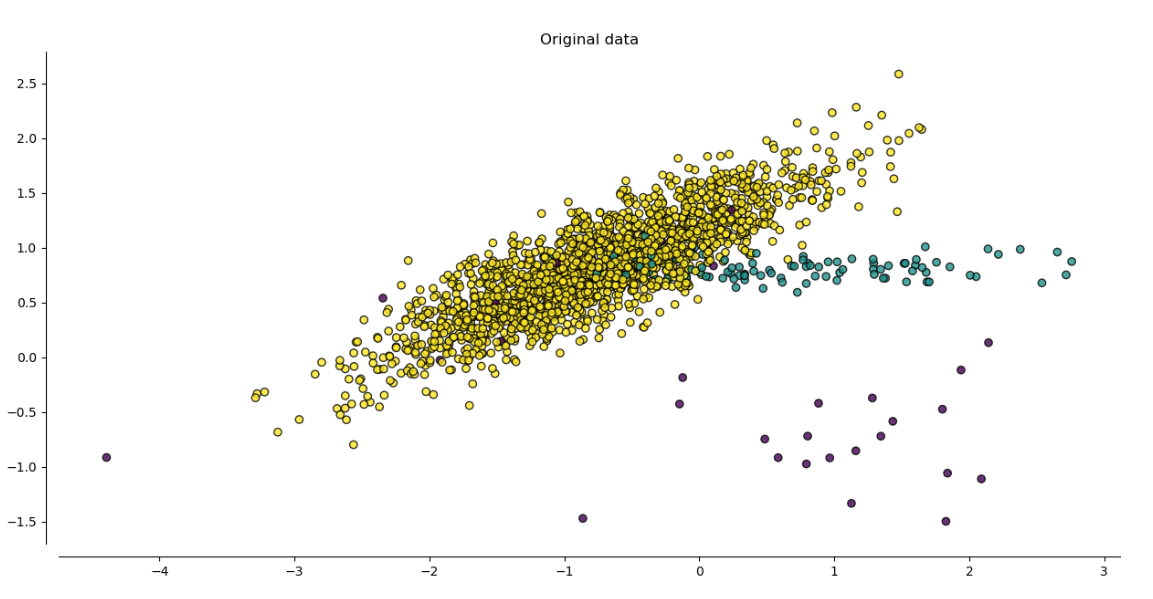
Let’s consider the data above as original data to showcase different techniques of generating synthetic data. We have 3 classes, yellow is the majority and the rest are minorities. We will show you how the generation methods affect the number of samples.
1. SMOTE (Synthetic Minority Oversampling Technique):
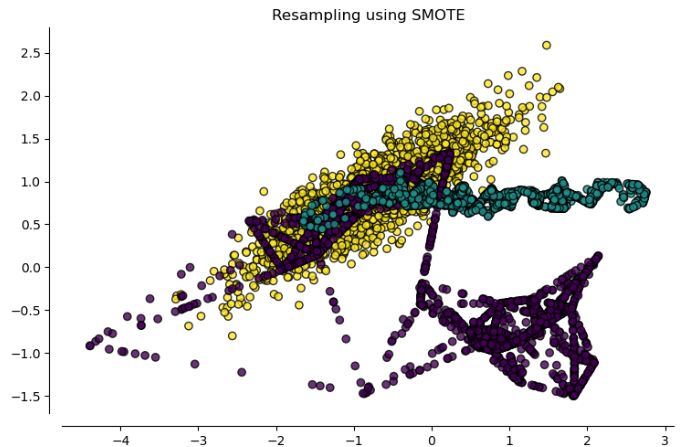
Firstly, a random sample of the minority class is selected, then via kNN algorithm its k nearest neighbors are found. Next a random sample within this k neighbors is chosen randomly in order to generate synthetic samples between them in the feature space; these new instances are a convex combination of the selected instances. The process is repeated several times among all the samples to create as many instances as wanted and usually combined with undersampling of the majority class.
It might appear unwanted data generated among the outliers that do not truly represent the reality. So if we face a database with several outliers we should be concerned that a deficient performance of SMOTE is possible.
2. Borderline SMOTE:
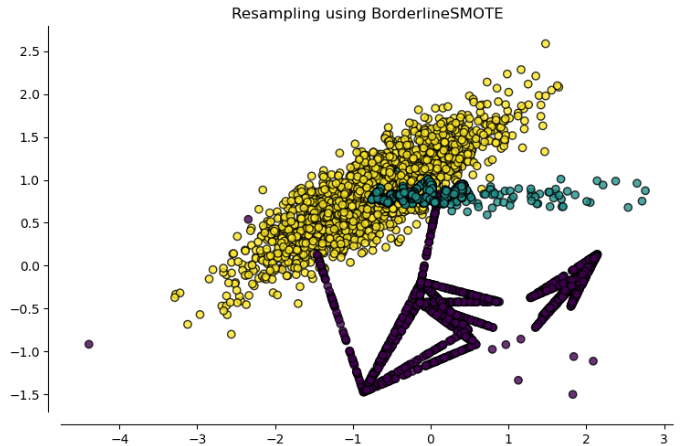
To solve the problem of outliers in our data there are alternatives of SMOTE. Borderline SMOTE is one of them. It begins by detecting the outliers, these being the minority class samples in which their k nearest neighbors belong to the majority class. Then it only creates the synthetic data among the rest of samples.
The optimal time to apply borderline-SMOTE is when we are aware that boundary decisions are frequently subject to misclassification. If not, we could continue using the standard SMOTE.
3. KMeans SMOTE:
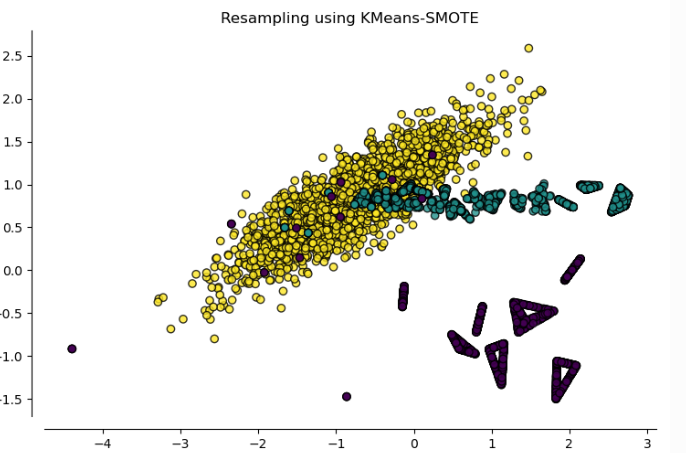
This variant avoids the generation of noise by generating samples in crucial areas of the input space. The process begins by doing clustering of the minority class using the KMeans, then a filtering is applied where only the clusters with more samples of the minority class are selected to finally generate the synthetic data among those, using SMOTE.
One problem that could emerge from this resampling is that all of the instances are highly concentrated in a few areas of the feature space and for instance, variance will be lost.
Example uses of synthetic data or real-world use

- NVIDIAOmniverse Replicator generates synthetic data to train autonomous vehicles to safely navigate the city by creating artificial people, animals or objects that cross in the direction of the car. This is a more complex type of synthetic data since consists in video simulation.
- Healthcare providers in fields such as medical imaging use synthetic data to train AI models while protecting patient privacy. For example, startup Curaitrained a diagnostic model on 400,000 simulated medical cases.
- The team behind Amazon’s Alexa AI system uses synthetic data to finish the training set for its natural language understanding (NLU) system. It gives them a firm foundation on which to train new languages in the absence of any or adequate data on client interactions.
- Synthesis AI uses synthetic data to help customers build advanced AI models for computer vision applications.
- Datagencreates synthetic datasets from simulations for a wide range of markets, including smart stores, robotics and interiors for cars and buildings.
- CVEDIAincludes Airbus, Honeywelland Siemensamong users of its customizable tools for computer vision based on synthetic data.
Final thoughts
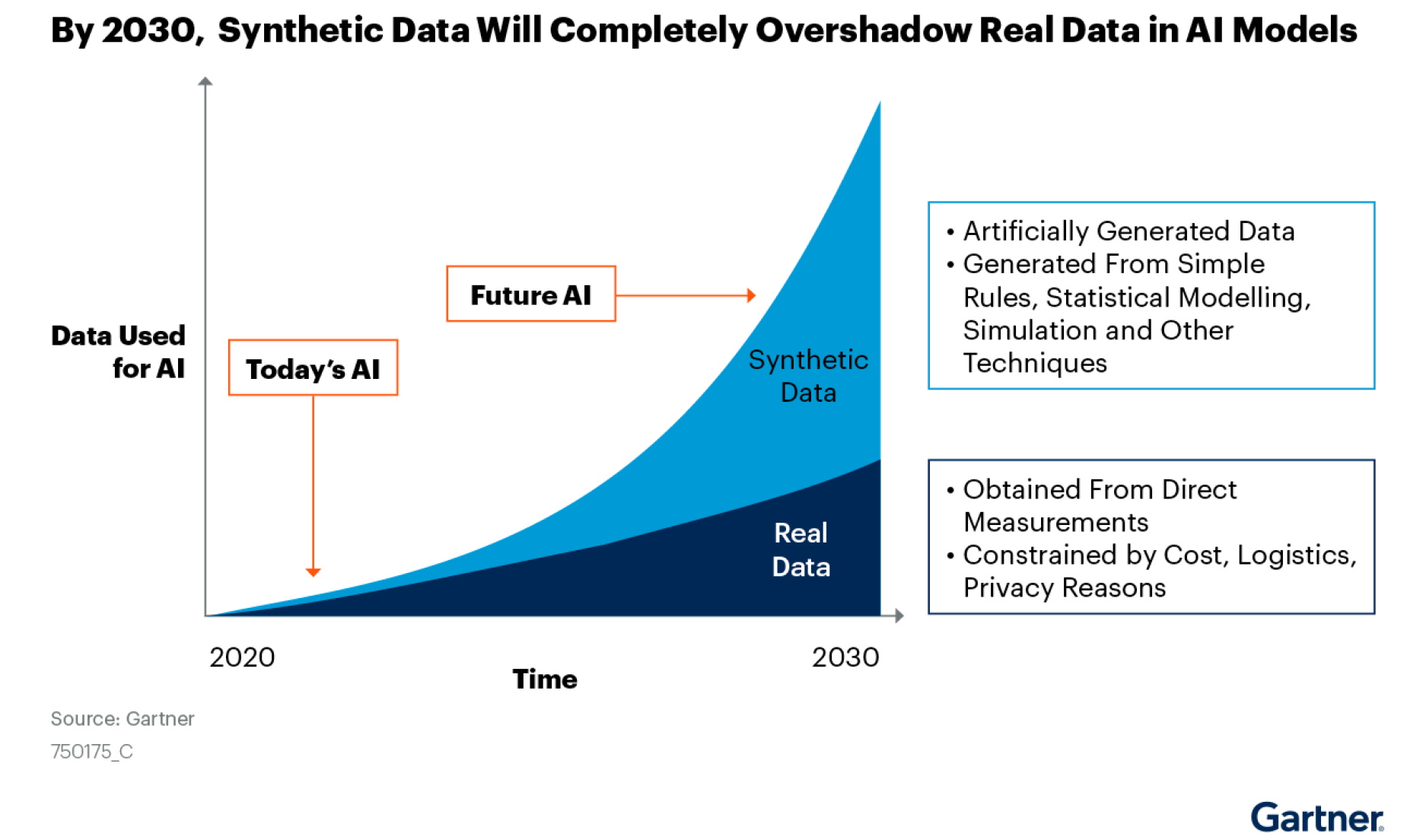 Synthetic data will become the main form of data used in AI. Source: Gartner, “Maverick Research: Forget About Your Real Data – Synthetic Data Is the Future of AI,” Leinar Ramos, Jitendra Subramanyam, 24 June 2021
Synthetic data will become the main form of data used in AI. Source: Gartner, “Maverick Research: Forget About Your Real Data – Synthetic Data Is the Future of AI,” Leinar Ramos, Jitendra Subramanyam, 24 June 2021
Despite being artificial, a research indicates that synthetic data can sometimes perform just as well (if not better) than actual data when it comes to training AI models. As you can see in the chart done by Gartner, the 60% of the data needed to construct AI and analytics projects will be artificially generated by 2024. By 2030 most of the data used in AI will be artificially generated by rules, statistical models, simulations or other techniques. Obviously real data will not disappear, it would continue to be needed in various projects and companies that could not benefit significantly from synthetic data.
Synthetic data has arrived to stay and will continue getting better and better. Companies benefit greatly from this technology, as well as all the data scientists and machine learning engineers that do not have to face the problems of collecting and cleaning real data.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.