
“Elvis singing about product analytics digital art” by DALLE-2
The last decade has seen great tools like Segment, Mixpanel, Amplitude and Google Analytics become key components of every companies cloud data stack. The problem with these tools is that by default, most of the analytics we collect sits idly. I believe the next decade will be different — it will become the norm for companies to make use of their data and personalize all of their user experiences by default with machine-learning. Before I explain why, let’s discuss three reasons why it’s so difficult to act on analytics with machine-learning today.
1. Uncertainty around whether you have enough data
“How much data do I need for machine-learning to work?” is one of the top questions we get asked at Shaped. Almost all companies we talk to are collecting analytics and user interaction data but there is still a deep seated fear that there isn’t enough of it for machine-learning to work. This is a legitimate concern because traditional machine-learning techniques required extremely large data sets to overcome the cold start problem. This uncertainty typically results in pushing machine-learning projects to next quarter or year when of course, there will be more data and users than there are today.
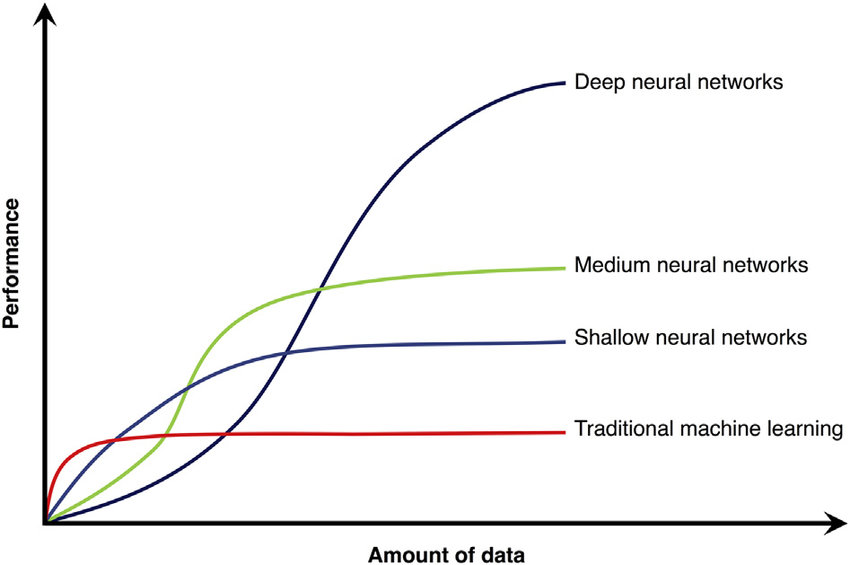 Broad data requirements for different models fromhttp://blog.easysol.net/building-ai-applications
Broad data requirements for different models fromhttp://blog.easysol.net/building-ai-applications
2. Data inertia
The actionability of analytics is slow because there are many hurdles between the initial analysis and the product change. Machine learning systems allow these hurdles to be skipped by immediately taking data insights and driving product change. Whereas utilizing analytics data sometimes feels like pushing a rock up a hill — there is a significant amount of inertia. To determine what to improve, a project needs to be set-up and time needs to be dedicated for formal investigation. For example, this might look like a few days of SQL analysis to develop a story, convince a product manager, organize the engineering resources and then several weeks to design and implement the changes into production.
 Pushing a rock up a hill is how I feel sometimes about analytics
Pushing a rock up a hill is how I feel sometimes about analytics
3. Building and maintaining machine-learning systems is challenging
Most companies are aware of the huge opportunity that utilizing analytics presents to personalize their product experience and improve conversion and engagement. However after looking into what would be required to DIY it becomes clear that it’s a gargantuan task. A team of people are needed to build, experiment and maintain machine-learning systems in production. Typically that looks like a combination of data engineers, data scientists and machine-learning engineers. Plus a 12+ month initial upfront investment. Will it pay off? How many models and experiments will we need to try out before landing on something that works? In addition, machine-learning engineers are costly and hard to hire — accounting for just ~1% of all software developers. Another problem is that off-the-shelf solutions like AWS Personalize or GCP Recommender aren’t all that easy to use. They require a lot of work to coerce all of your data (e.g a customer data platform like Segment or Mixpanel) into their data stack, a surprising amount of maintenance, struggle with the cold-start problem and are a black box — companies tell us they’re not really sure what’s going on with their models.
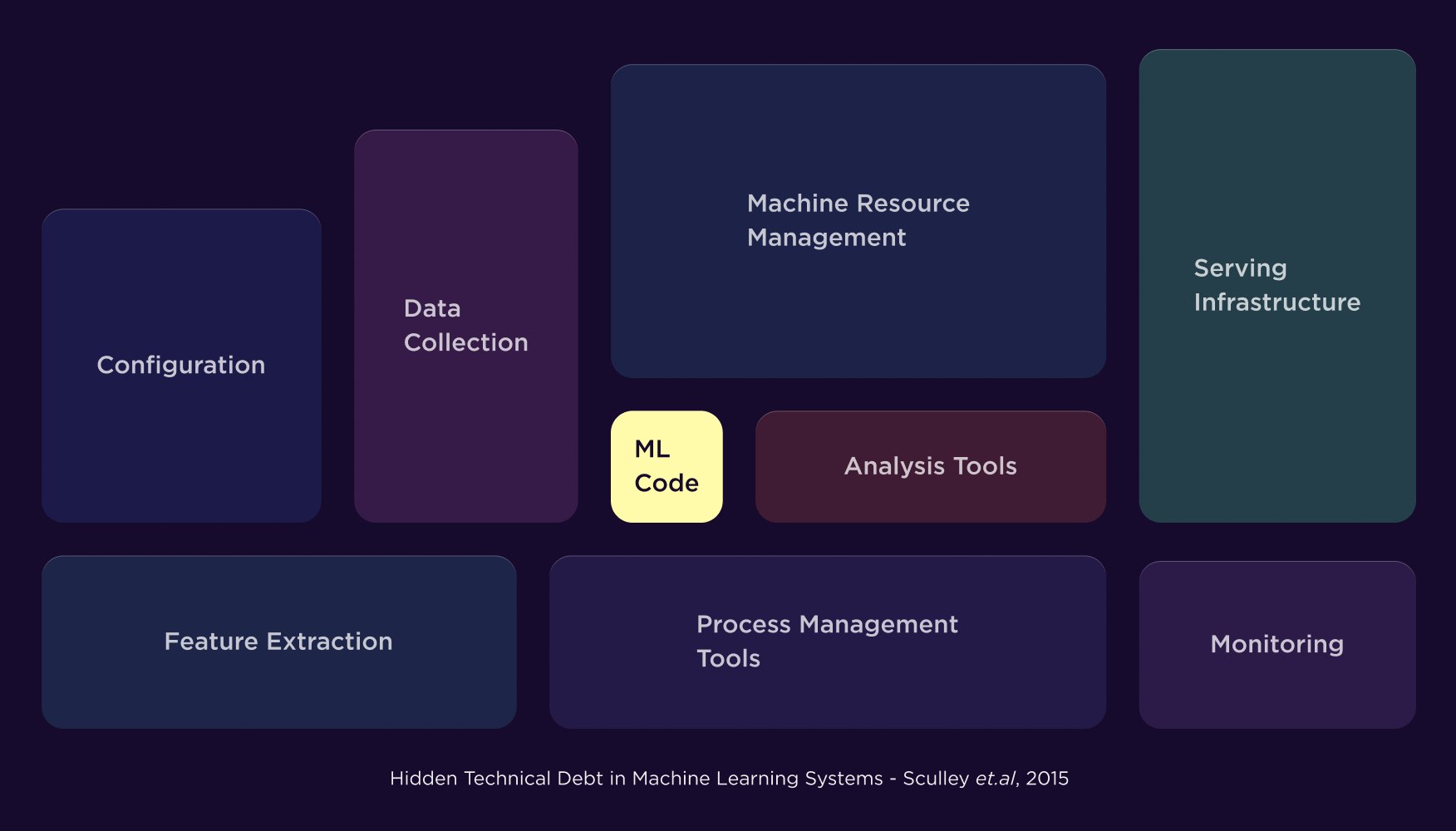 Building a model is only 5% of the work of productionizing machine-learning
Building a model is only 5% of the work of productionizing machine-learning
The good news is that all three of these issues are going away quickly! 🥳
1. Transfer learning means companies don’t need as much data
Transfer learning lets us stand on the shoulders of giants. Irrespective of the size of your dataset, transfer learning and newer machine learning techniques enable a higher start point, slope and asymptote. The models we use at Shaped are pre-trained so our customers don’t have to worry about the cold-start problem being a limiting step. Once we’ve connected to a customers data source we then re-train and fine tune our models so that they’re customized. For those looking to tinker, huggingface is a wonderful community of open sourced machine-learning models to explore. All in all, transfer learning means that the minimum data required for excellent machine-learning results has shrunk considerably over the last decade.
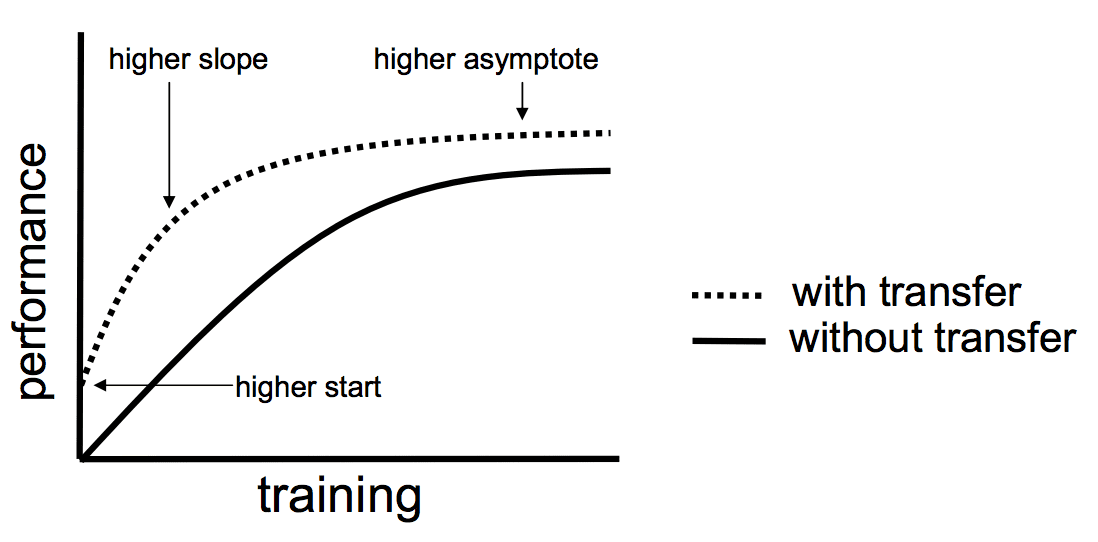 Transfer learning is a game changer forperformance
Transfer learning is a game changer forperformance
2. Anti-inertia by default
Machine-learning systems for use cases like ranking and recommendations are by design anti-inertia — they are constantly improving the end-users experience with every piece of data collected. The monitoring and analysis of machine-learning embeddings (numerical representations of data — see the appendix for a graphic) can also reveal complex trends in your product that low-level analytics dashboard are incapable of providing. For example, visualizing your embeddings can show the similarities of your user cohorts or break down the dimensions of importance of your content. This has huge potential to be a source of business intelligence for many companies that is currently untapped. Another game-changing possibility is that embeddings can generate new products or content ideas and even predict the demand for it. More on that for discussion in another post.
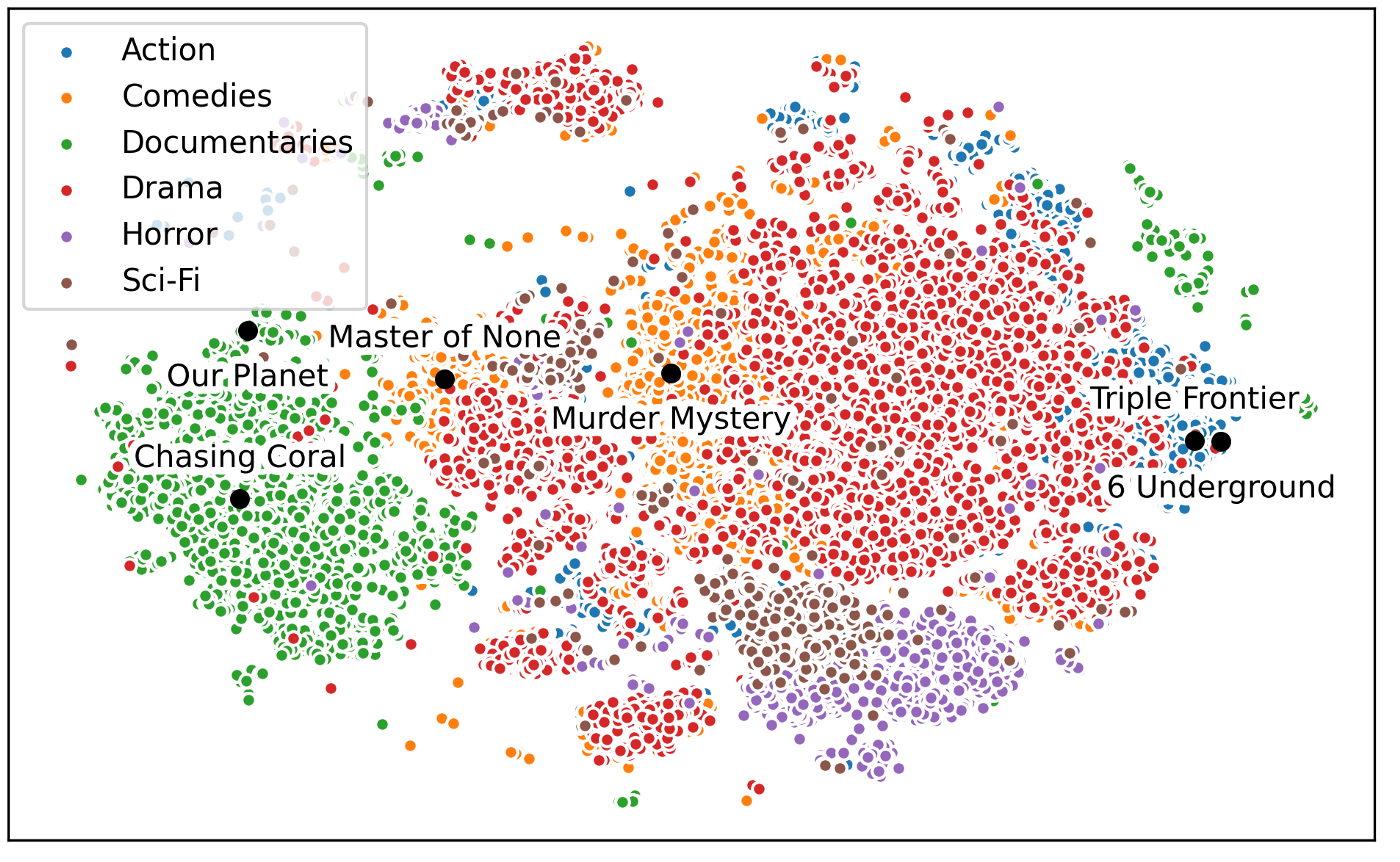 It’s fascinating to visualize embeddings of the Netflix library of movies and their genre.T-SNEvisualization of embeddings learned from content categorization task fromNetflix technology blog
It’s fascinating to visualize embeddings of the Netflix library of movies and their genre.T-SNEvisualization of embeddings learned from content categorization task fromNetflix technology blog
3. Next wave of machine-learning companies
Companies like Shaped, Pinecone, Mage and Continual have made it considerably easier to experiment, vectorize and productionize machine-learning. This is saving months or years of build and maintenance time. Still, the machine-learning ecosystem is young and emerging. It could be compared to the state of early 2000s cloud infrastructure as AWS was entering the market.
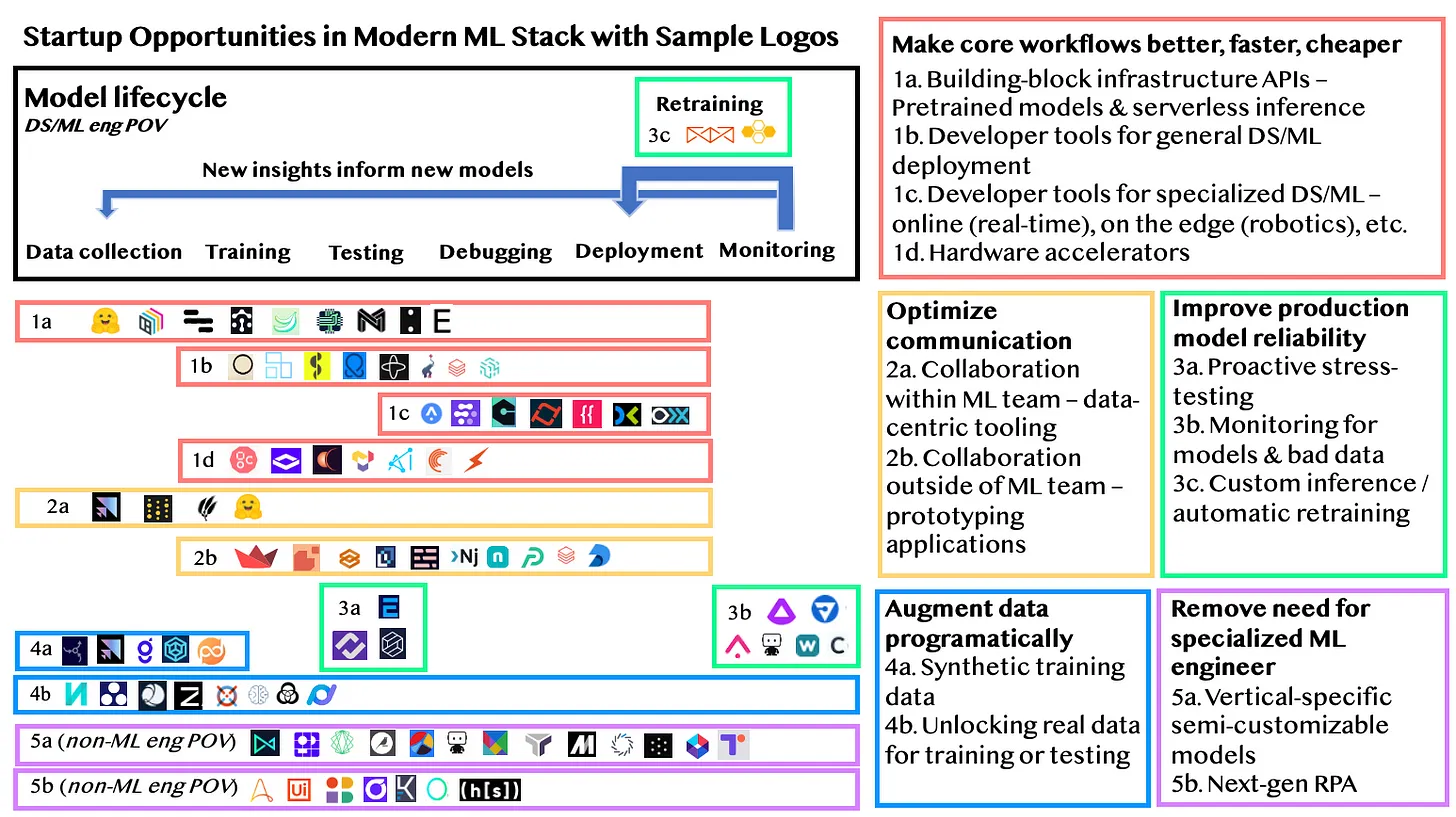 The machine learning eco-system is rapidly expanding. This graphic by Leigh Marie Braswell from her excellentStartup Opportunities in Machine Learning Infrastructureblog post
The machine learning eco-system is rapidly expanding. This graphic by Leigh Marie Braswell from her excellentStartup Opportunities in Machine Learning Infrastructureblog post
My 2 cents — don’t wait, act now!
You can build a ranking model with Shaped and go from 0-1 in a few hours. You’ll likely be pleasantly surprised how far you can get with little data and effort. Once you have results from your first model it’ll become clear where opportunities to iterate are. Some of our smallest customers are pre-launch, private beta or pre-seed companies with <1000 users. When these companies scale, their feeds and recommendations will be personalized from day 1. This is becoming the norm because products like TikTok have dramatically lifted users expectations of personalization. Even Amazon is testing a new TikTok style feed in their app. For the team at Shaped it’s exciting that we are able to help all companies big or small utilize their analytics data to personalize their product experiences with machine-learning.
What do you think? Has your company got analytics data sitting idly in a data warehouse? Or have they thought about implementing machine-learning but decided to wait because it seemed too difficult? Email me atdaniel@shaped.aiif you want to get in touch
Appendix
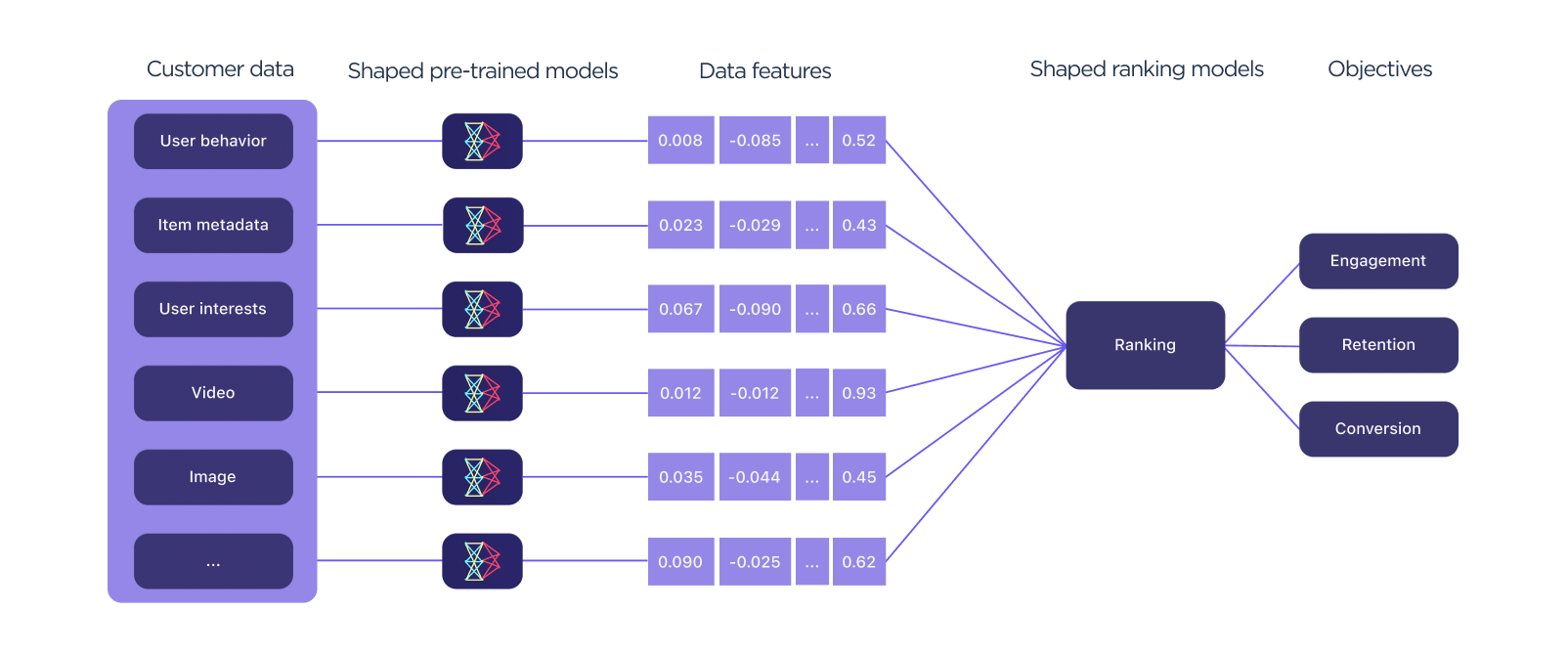 Examples of the transformation of data with neural networks to embeddings (listed here as data features) powering a ranking model fromdocs.shaped.ai/reference/architecture
Examples of the transformation of data with neural networks to embeddings (listed here as data features) powering a ranking model fromdocs.shaped.ai/reference/architecture
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.