.png)
Whisper 🤫 : A multilingual and multitask robust ASR model
Introduction
Natural Language Processing (NLP) is a term that we read often in the media. It seems like everyday, there’s a new breakthrough coming up on my social media feed. For Automatic Speech Recognition (ASR), a subfield of NLP, one of the last advances is a new model proposed by OpenAI: Whisper, a multilingual and multitask neural model with billions of parameters. This model can transcribe and translate English audio into 96 languages, along with other tasks such as text normalization, language identification, and voice activity detection.
The architecture of this neural model is an encoder-decoder Transformer-based neural network that, differently from the unsupervised models based on wav2vec, is trained with 680,000 (weakly) supervised hours of audio collected from the web. While wav2vec has provided exceptional results, even more if we talk about low-resource languages, the authors of Whisper argue that this unsupervised model requires non-straightforward fine-tuning to be helpful for a particular task, for example speech recognition on a low-resource language.
The authors of Whisper then coped with the problem of ASR by following a supervised approach but with some required remarks. As previous works have shown: a) using several datasets/domains helped the performance of the ASR system, and b) weakly and maybe noisy but abundant data can also improve de quality of the output of the ASR system. These findings paved the way to use this vast amount of web-crawled data from several domains, along with the non-verbatim transcriptions that came with it. But they didn’t stop there, as they included multilingual data in almost 100 other languages to allow the model to learn the transcription and translation tasks jointly.
Data filtering
Regarding data filtering, some interesting points to highlight are:
-
Weakly standardization of text, using transcriptions almost as-is.
-
Removal of automatic transcriptions from other ASR systems to avoid biasing the system to this automatic output.
-
Language identification to clean (audio, transcription) pairs that do not match.
-
Audio files split in chunks of 30 seconds, including voice-empty segments that they use for the Voice Activity Detection (VAD) task.
Model architecture
When it comes to the architecture, they do not use an overly complex setup, but a set of Transformer encoder blocks providing the cross-attention scores to the decoder, also based on Transformer. This way, they focused on the supervised training method isolating any modeling effect.
One of the most exciting parts of this work is the multitask orientation of the model, coping not only with ASR but with several related tasks, such as speaker diarization or VAD. With this integrated perspective, the authors proposed a token-based interface to identify and select the task during training and inference. The following figure illustrates some examples of the sequences they used to feed the model during training, along with the audio-conditioned input via the encoders blocks.
 Example of a token sequence for an English transcription with timestamps (English speech transcription task).
Example of a token sequence for an English transcription with timestamps (English speech transcription task).
Here, the input tokens are provided with the timestamps and the previous context of this sequence (”as i”). Another example for the VAD task, where the model aims to determine if the segment contains speech or not, with an example of not having speech. In this case, the encoder may receive, for example, a music segment.
 Example of a token sequence for a non-speech input (Voice Activity Detection task).
Example of a token sequence for a non-speech input (Voice Activity Detection task).
This last example illustrates how it is encoded in the translation task, indicating the language identifier and the word sequence without including, in this case, the timestamps.
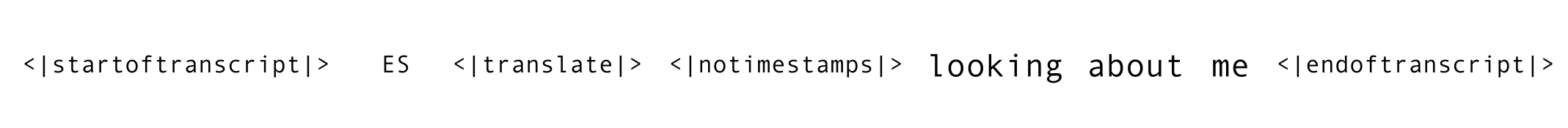 Example of a token sequence for a Spanish (ES) to English (EN) translation without timestamps (Speech translation task).
Example of a token sequence for a Spanish (ES) to English (EN) translation without timestamps (Speech translation task).
Results
Competitive performance along many domains
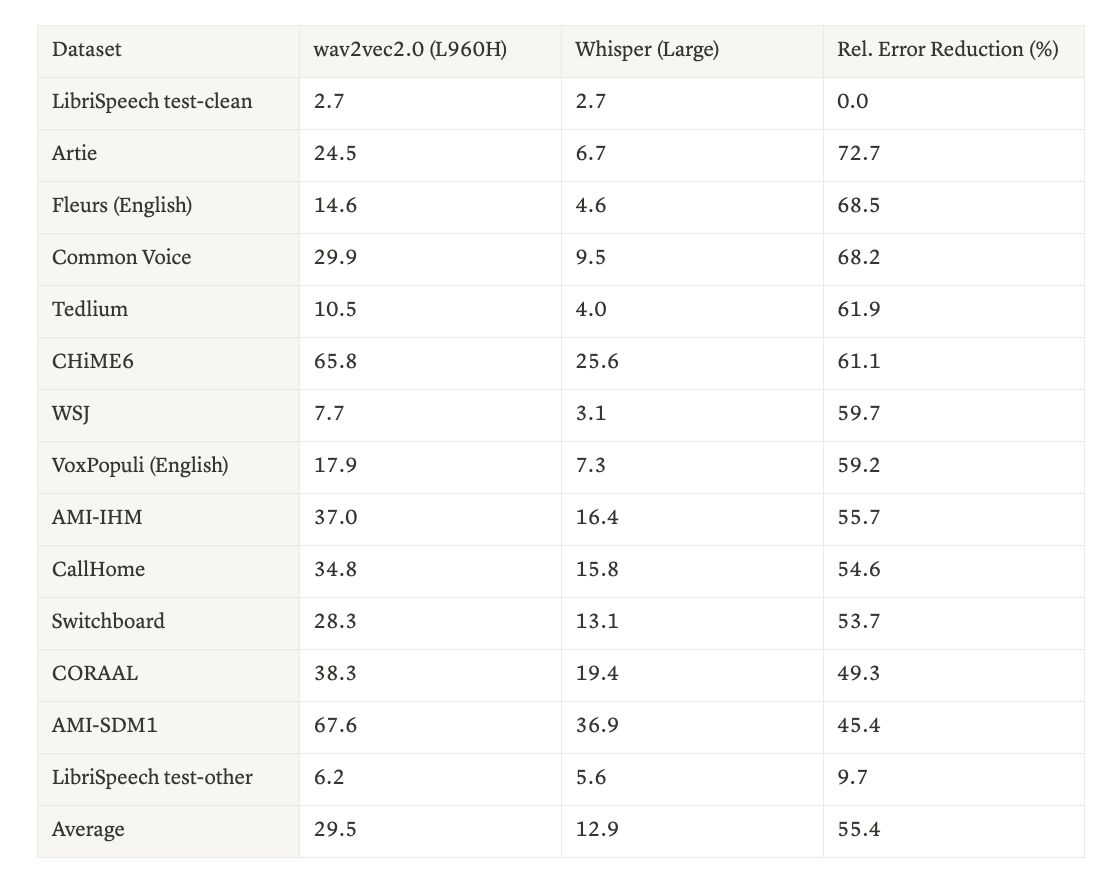
The authors discussed the robustness of the model, evaluating their proposal along many different datasets and illustrating the multi-domain capabilities with zero-shot competitive performance. The following table compares the Whisper model (Large version - 1550M params) with the wav2vec2.0(Large 960h), with the same performance on the well-known LibriSpeech test-clean but with a relative improvement of 55% across the other out-domain selected datasets. The metric here is the Word Error Rate (WER), an error measure (the lower the better) that reflects the minimum number of edit operations (insertions, deletions and substitutions) to transform from the proposed transcription to the correct text. According to these results, the proposed Whisper model provides an excellent out-of-distribution robustness.
Regarding the multilingual capacity of the model, while Whisper provided impressive results for the low-data benchmark Multilingual LibriSpeech, the results for other state-of-the-art models on the Eurparl-based dataset VoxPopuli are still far behind.
Weakly-supervised multitask model
When it comes to translation, Whisper model demonstrates good performance on the CoVoST2 task in low and medium-resource settings, outperforming models trained with this limited in-domain data. However, it did not improve the results for the models trained on high-resource languages.
Regarding language identification, the comparison they performed obtained around 80% accuracy for 82 languages from the Fleurs dataset. However, they could not compare with other state-of-the-art methods as Whisper only partially covered the languages included in this dataset.
They also tested the noise robustness of the model, including white noise and pub noise (ambient noise from crowdy environments), showing its good performance and robustness in this potentially noisy environment.
Long-audio speech recognition performance
As Whisper is trained on 30-second audio chunks, the authors wanted to evaluate its performance on long audio sequences; this is the expected input for real-world tasks, such as lectures or complete TV shows. To do that, they apply a transcribe-and-shift where they transcribe the input and then shift the 30 seconds window according to the predicted timestamps, to transcribe the next chunk adequately synchronized. They compared their results with both open-source models and commercial ASR APIs. The results demonstrated that this model offers an out-of-the-box competitive performance along several long-audio-based datasets.
Conclusions
OpenAI has provided a competitive ASR model leveraging around six thousand hours of weakly supervised data from the web to train a model in a multilingual and multitask fashion, using a token-based interface to train and interact with the model. They have demonstrated that an integrated model trained this way can achieve almost state-of-the-art performance on speech transcription. Additionally, this last breakthrough in ASR provides a robust neural model not only for this English speech recognition task but also for multilingual speech recognition, speech translation, language identification, and VAD, with impressive results along all these tasks.
If you want to try this model yourself, OpenAI released their tools to perform the transcription via CLI or Python in its repository.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.