Why is TikTok’s feed so addicting? The secret lies in their recommendation engine, it’s precisely what made TikTok one of the largest social media platforms. Seemingly the feed can read your mind and keep you in the app for longer. Recently TikTok decided to let everyone in on a secret and released its model Monolith in a paper titled: “Monolith: Real-Time Recommendation System With Collisionless Embedding Table”.
Online recommendation systems are algorithms that are used to make personalized suggestions to users based on their interests and preferences. These systems are commonly used by online retailers and media companies to recommend products or content to their users. In this post, we’ll dive into the inner workings of TikTok’s awesome recommendation system and learn what makes it one of the best in the field!
What is the problem with current designs?
Building scalable, real-time recommendation systems is vital for many businesses to build great experiences within their products or websites. However, current deep-learning frameworks (TensorFlow or PyTorch) don’t work well for real-time production scenarios. This is because:
- Updating models based on static parameters and dense computations is unsuitable for good performance in recommendations, which rely on dynamic and sparse features.
- Common approaches are designed with a batch-training stage and serving stage (during user interaction with the product) wholly separated, preventing the model from interacting with customer feedback in real-time.
TikTok’s team explains their solution in 3 steps:
- They crafted a collisionless embedding table while further optimizing it by adding expirable embeddings and frequency filtering to reduce its memory consumption, making it efficient and suitable for deployment to users;
- They provided a production-ready online training architecture with high fault-tolerance
- They experimentally proved that system reliability could be traded-off for real-time learning
Sounds intimidating? Not to worry, we will go through every single component and break it down, by the end of this article you will confidently understand why you can lose hours upon hours in the app. Ready? Here we go.
Embeddings and Hash maps
Researchers at TikTok made the observation that for recommendation systems the data is mostly categorical and sparse. This means that if we were to embed the data using an ML approach like word embeddings we would not be able to do so with the number of unique features that data for recommendation provides, in comparison the language models can get away with it due to limited vocabulary size. Using practical experience from the recommendation systems of YouTube and Instagram the hashing trick was decided to be an optimal approach for a large-scale recommendation system. Let’s dive into the specifics of the one used in Monolith.
But what about a HashMap?
A hash map is a data structure that allows very fast mapping via a special hash function of some piece of data to a value.
Hash maps are fast and are used by large platforms to efficiently encode the data, so how does Monolith make it better? Hash maps suffer from an inherent tradeoff that comes with an original design of this data structure called a collision.
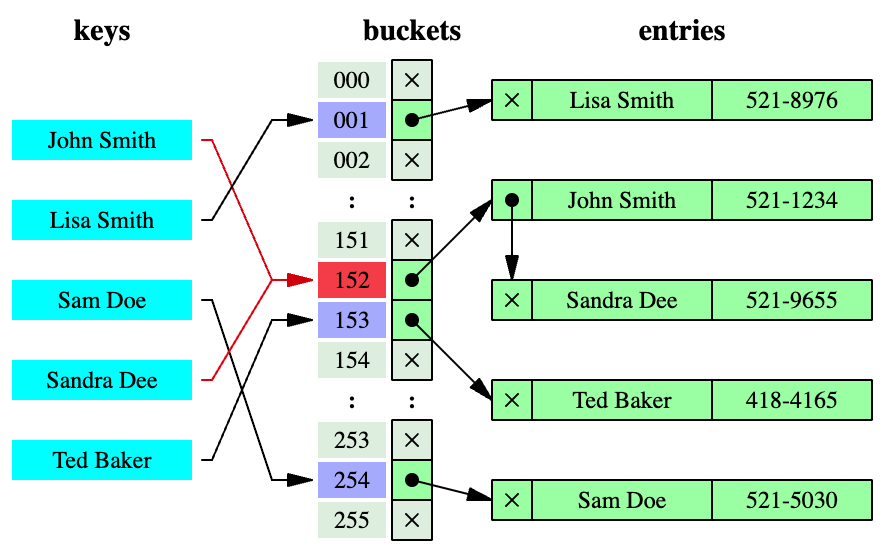 Hash map illustration
Hash map illustration
A collision occurs when two or more pieces of data are mapped to the same output value by a hash function. This can cause problems when using hash functions to index data, as multiple pieces of data will be mapped to the same location. TikTok’s team developed a cuckoo hashmap to address this.
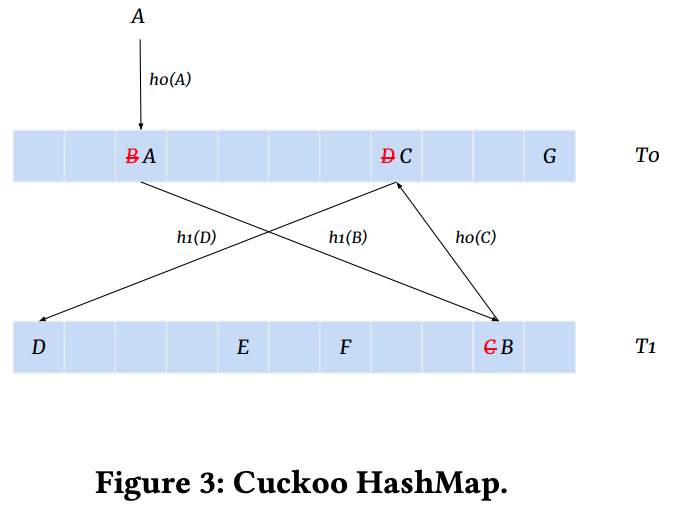
In a cuckoo hash map, just as in a standard hash map each piece of data is assigned a unique key, and the key is hashed to determine its location in the array. If the location is already occupied by another piece of data, the existing data is “kicked out” (similar to a real-life cuckoo behavior of cuckoo in relation to eggs in the nest) and has to find a new location in the array, using a second hash function. This process continues until all the data has been successfully inserted into the array, or until a maximum number of iterations is reached. An example is illustrated above. Here two hash tables T0 and T1 used to store the hashed data. A value A is hashed and inserted in T0, but as B already occupies this place it is then evicted and an attempt is made to insert it in T1, this process will repeat until all values are inserted or the rehashing happens to avoid cyclic insertions. This process allows for the avoidance of collisions and it has a significant effect on the performance of the production model.
To complete their embedding system design researchers added a few bells and whistles to further optimize the process, in particular, to cut the memory requirement that hashing would require:
- A probabilistic filter to filter IDs in the hashmap. Since an important observation is that in data from TikTok IDs are long-tail distributed, where popular IDs may occur millions of times while the unpopular ones appear no more than ten times, there is a reasonable assumption to be made that they will not affect the final model quality and therefore can be cleared.
- An ID existence timer that controls the erasure of old and stale IDs. This could possibly be due to a user that is no longer active, or a short video that is out-of-date. Storing embeddings for these IDs could not help the model in any way so it is sensible to clear the memory.
Online Training
Now as we learned how the data is represented inside the model we need to understand how it is trained and updated. The overall diagram of the Monolith online training architecture can be found below:
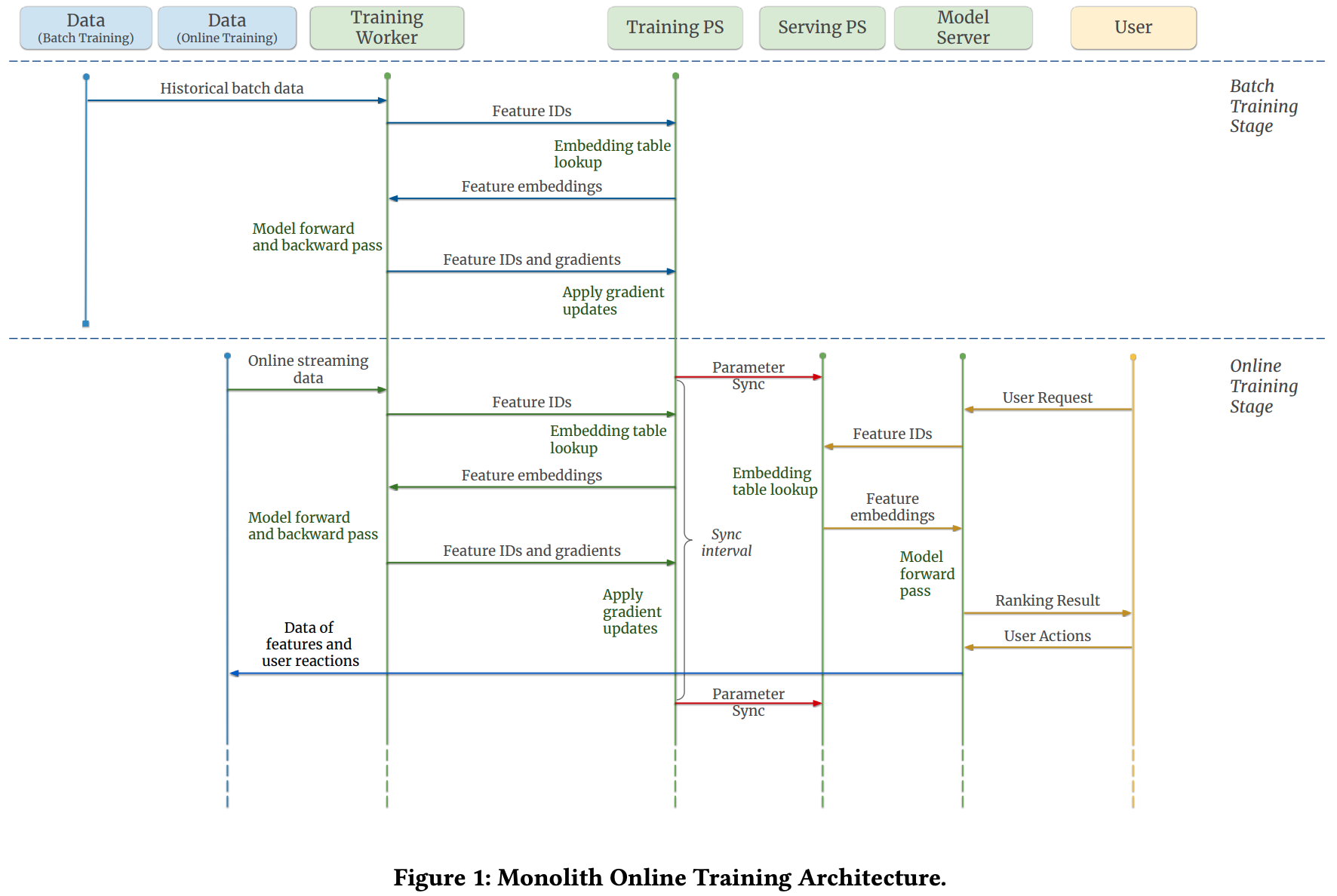
It looks complicated but actually, it all revolves around a very simple process that is the basis for the larger architecture and that drives the core of the overall training architecture.
TensorFlow’s distributed Worker-ParameterServer (or simply PS) model is a way of training machine learning models in a distributed fashion, where multiple machines (or processes on a single machine) work together to train the model, illustrated below:
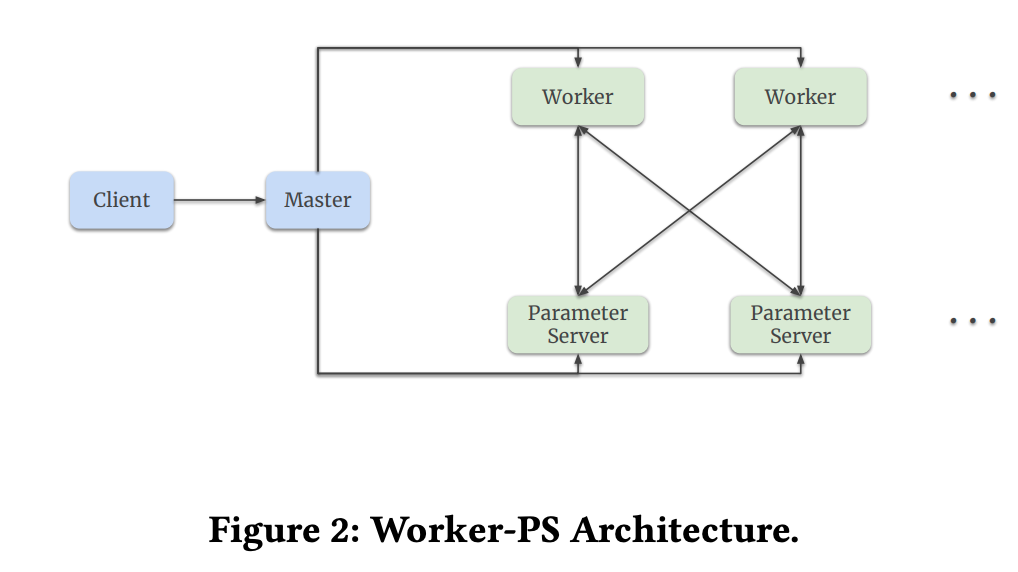
In this model, there are two types of processes: workers and parameter servers. The workers are responsible for performing the computations required to train the model, such as calculating gradients or updating model parameters. The parameter servers are responsible for storing the current state of the model, such as the model weights or biases.
The training is divided between batch training and online training stages:
- Batch training stage. This stage works as follows: in each training step, a training worker reads one mini-batch of training examples from the storage, requests parameters from PS, computes a forward and a backward pass, and finally pushes updated parameters to the training PS. Batch training is useful for training historical data when there is a need to modify model architecture and retrain the model;
- Online training stage. After a model is deployed to online serving, the training does not stop but enters the online training stage. Instead of reading mini-batch examples from the storage, a training worker consumes real-time data on-the-fly and updates the training PS. The training PS periodically synchronizes its parameters to the serving PS, which will takeeffect on the user side immediately.
Streaming engine
To make sure that Monolith can seamlessly switch between batch training and online training it was built with a streaming engine component:
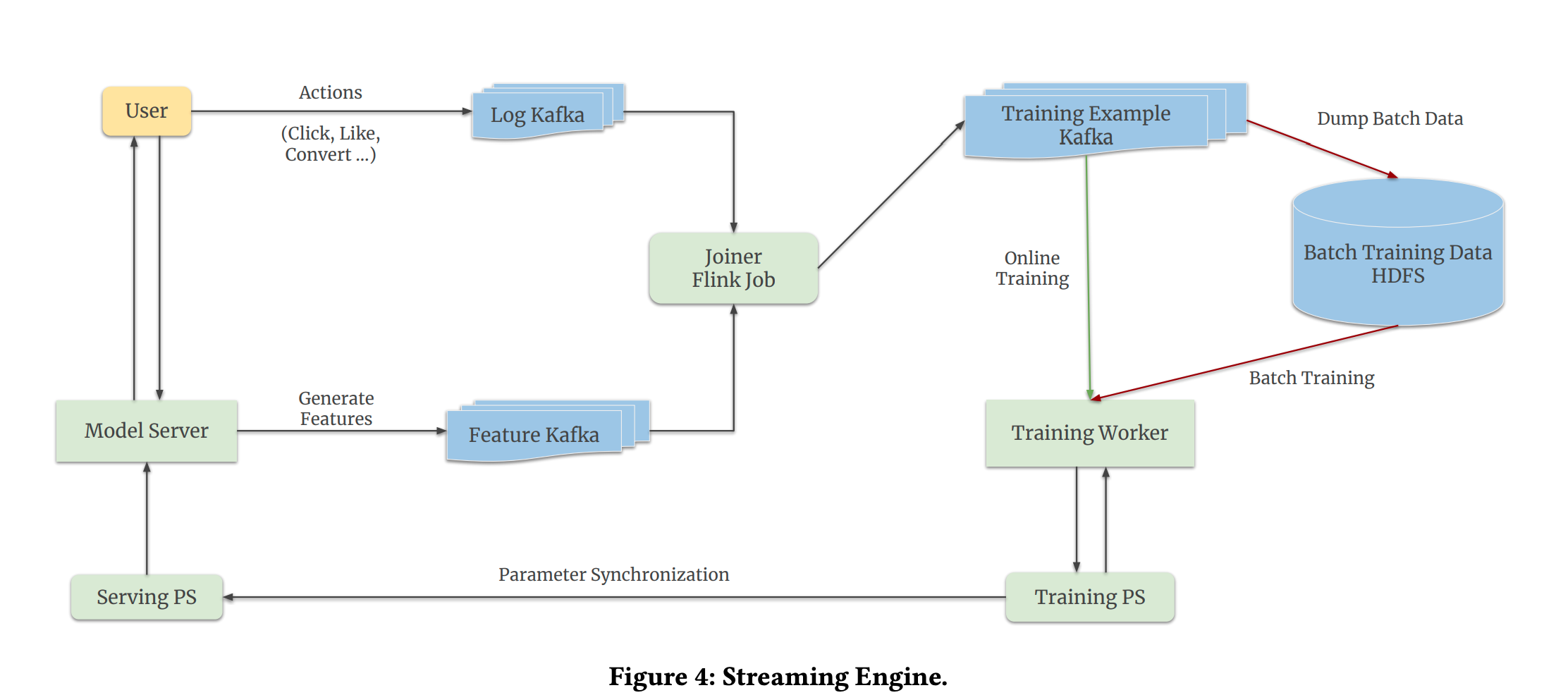
In order to gather real-time user feedback for further training the research team used Kafka queues, one queue logs the user actions (click’s, likes etc.) another one is for features coming from a model server. Then two are joined by using Apache Flink joiner, this data packed is transformed into the training data that is then is read by another Kafka queue, those training examples are used for both batch training and online training:
- During batch training, data from the Kafka queue is dumped to Hadoop Distributed File Storage (HDFS), after a certain amount of training data is accumulated it is then sent to the training worker
- For online training the process is simpler: the data is just read directly from the Kafka queue
After the training operation is performed a PS collects parameters and according to a selected synchronization schedule updates the serving PS which in turn updates the model on the user side.
Online Joiner
The joiner process is actually a bit more complicated and we should note a few things about it:
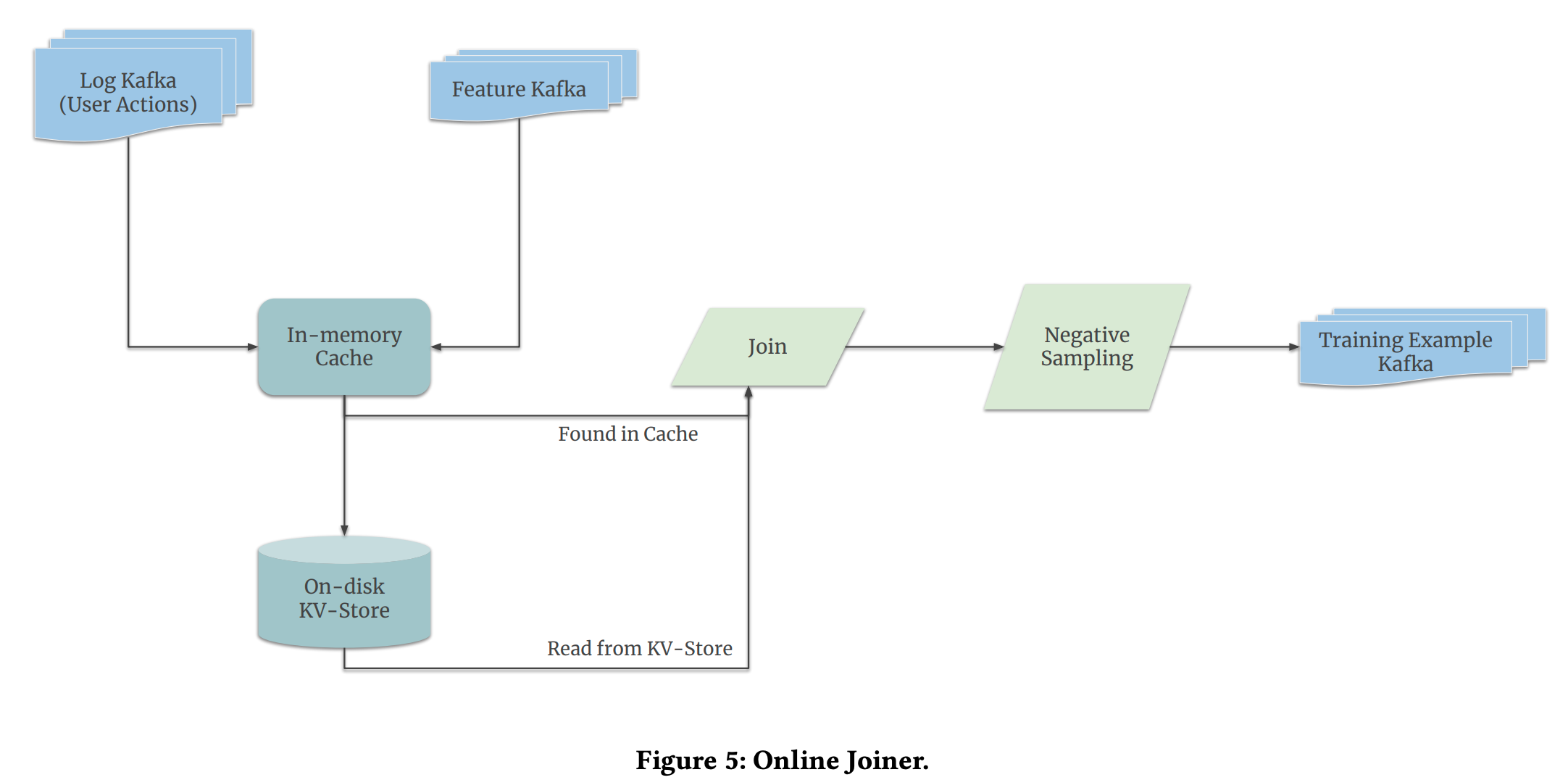
In-memory cache and KV(Key-Value)-store, are two components that help stabilize the latency between user actions and features coming from the server, this is due to the fact that they both arrive irrespective of each other’s arrival time, so caching is required to correctly pair them up. But what if the user takes a long time to complete an action? Then caching would not be such a great idea, hence some values are stored on the disk to be paired up again. When a user action log arrives, it first looks up the in-memory cache and then looks up the key-value storage in case of a missing cache.
Note also one last step which is Negative Sampling. As there are positive and negative examples during training. In a recommendation system, positive examples are items that a user likes or has shown interest in, while negative examples are items that the user does not like or has not shown interest in. But their amount can be imbalanced therefore it is important to correct this bias in the dataset.
And that’s it! You’ve learned about all of the components in Monolith. Now for one last section where researchers prove the effectiveness of online learning on the fly.
Real-time Learning
Here the team also compared the performance of the model at different sync time intervals to verify the performance:
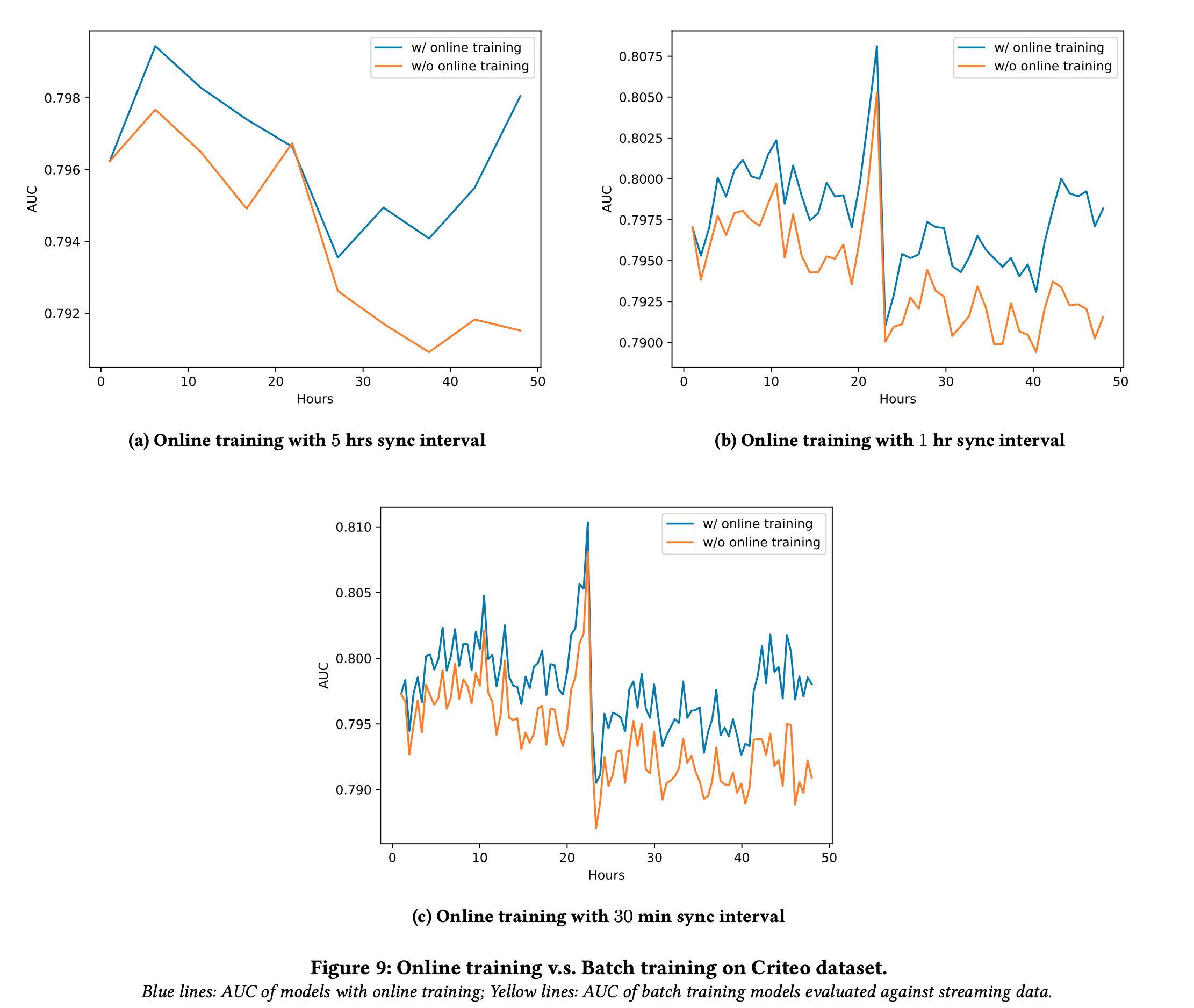
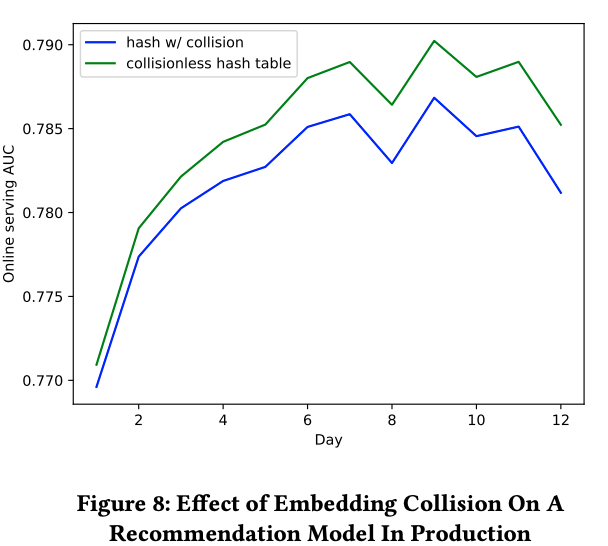
As we can see above online training is essential for better performance of a recommender system with dynamic feedback.
Thanks for reading
Thanks for reading my deep dive on how TikTok’s real-time recommendation system works. I hope you found it interesting and learnt something new. If you have any questions or would like to test a real-time recommendation system, feel free to reach out to the Shaped team at hello@shaped.ai
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.