
Going beyond simple
If you were to open your phone right now and pick a few apps at random, how many of those give you suggestions on what to do next? Buy? Listen to? Eat? With deep learning becoming more widespread so do we rely more on recommendation systems. Building a good one is by no means simple and there is plenty of evidence for that.
Would you pay for Spotify if it had no discovery features or would YouTube keep you entertained if there were no excellent suggestions for what to watch next? And let’s be honest we all have gone through a video rabbit hole at least once and often discovered something awesome. But to have this magical moment we need to rely on high performing RecSys pipeline.
To make a good RecSys engine we need to go beyond a simple model understanding. With this in mind, I would like to introduce you to a new episode of our ongoing series on RecSys metrics, where we look at essential ways of making your recommendations awesome. In this blog post, we will go beyond standard machine learning performance measurements and look at a key score that is essential for a deeper understanding of your model.
Serendipity or always being lucky
Sometimes you can get a day when you feel like you are on a roll, unexpected new things happen but they are all nice surprises that leave you happy, akin to always getting a good hand in blackjack. This analogy gives us a good understanding of what serendipity is.
💡 Think of serendipity as the “wow factor” 😮 in recommendations. It’s the feeling of being pleasantly surprised by a recommendation that you wouldn’t have thought of or didn’t know existed, but still resonates with your interests or preferences.
This is an important metric for recommender systems because it can enhance user satisfaction, engagement, and discovery, by providing novel and diverse recommendations. But measuring something as abstract as a “wow factor” seems very complex so let’s see how to formulate it next:

Where i is an item, meaning a sample of the content you are recommending.
💡 There is no industry-agreed standard on how to measure serendipity and various researchers and companies propose their own formulation. Here we will look at the very intuitive one.
Let’s break down two key terms next to see what they represent!
Relevance
Just as with serendipity, there is no agreed approach to measuring relevance.
A simple and very straightforward definition of relevance, where we only really care about an item if the user has interacted with it:
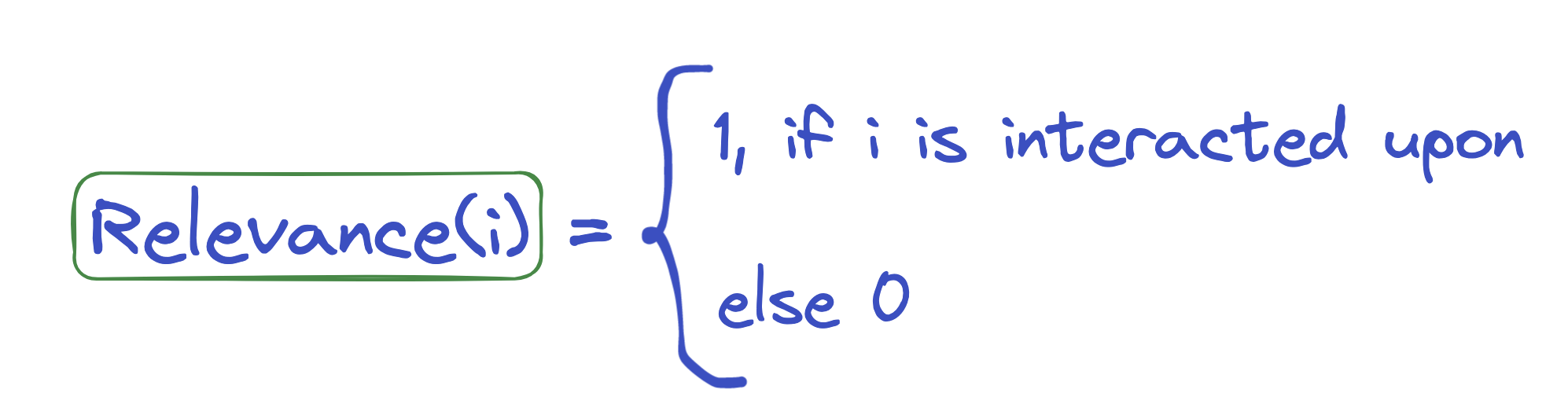
But immediately you see the problem, that this definition can be too rigid as focusing on an item that was interacted with (viewed, liked, clicked) with a discrete score gives little flexibility. Generally, relevance is measured as a function that estimates the degree of match or similarity between the recommended item and the user’s preferences, based on their past behavior or explicit feedback. What we might want to use instead of just 1 is a better way of defining similarity, for example, cosine similarity.
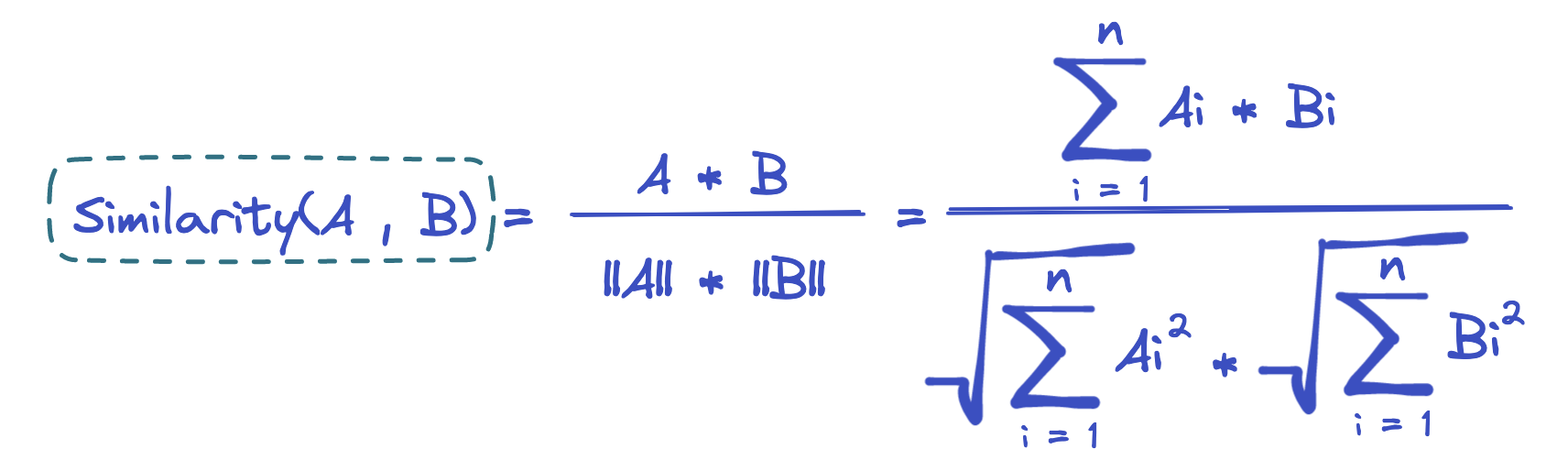
Which is nothing but a simple method from linear algebra to measure how similar two vectors A and B are. A can be an item or expression of items the user liked in the past and B can be a recommended new item. If the score of similarity is high it suggests that the user might find this item relevant.
Unexpectedness
One way to formulate unexpectedness is:
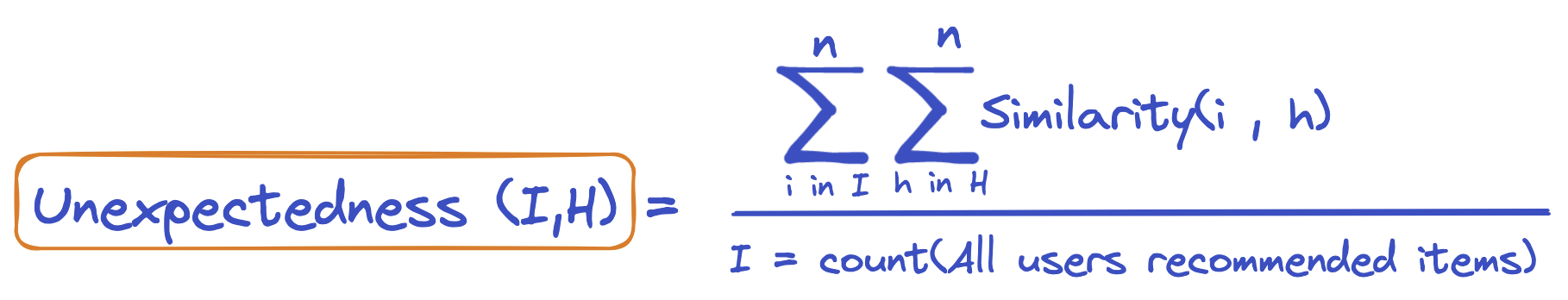
WhereIand H are the user’s recommended items and previous or historical item interactions respectively. Similarity scores of both are summed up and divided over all items.
You can say that relevance and unexpectedness both rely on similarity but we need to note that their respective similarity scores are measured between sets of different things. In practice, unexpectedness and relevance usually have a weight attached to them to customize the importance of these two factors.
To understand how serendipity gets used in real-life scenarios, imagine a music streaming service that recommends a song by a relatively unknown artist to a user who usually listens to mainstream pop music. The user may be initially hesitant to listen to the recommendation, but after giving it a try, they discover that they actually enjoy the song and start exploring more music by the same artist. This is an example of serendipity in action, as the recommendation introduced the user to a new and unexpected music genre that they wouldn’t have discovered on their own, but still found enjoyable. (I’m looking at you, Spotify Discovery Queue).
For a business, this can mean more time users will spend on a platform, higher retention, and as a result, more products or services purchased.
Overall, serendipity is an essential metric in recommender systems that aims to balance the trade-off between relevance and unexpectedness, by encouraging the system to suggest items that are not only relevant but also surprising or unexpected.
💡 Note the tradeoff between an item being relevant and unexpected at the same time. If you like country music then another country suggestion won’t be surprising to you, its relevance would be high. However, to give you a surprising recommendation the relevance score has to be lowered to allow for other genres to make a cut.
Putting it all together
Before we conclude this post there are 3 key points you should remember as a developer when using serendipity:
- Balancing: Serendipity is often used in combination with other metrics such as relevance and diversity, in order to balance the trade-off between novelty and usefulness. A recommendation that is too surprising and unexpected may not be useful to the user, while a recommendation that is too similar to previous items may be seen as boring or unhelpful.
- **Data quality:**Serendipity scores depend on the quality and relevance of the data used to train the recommendation system. Hence, you should ensure that the data is representative of the user population and that it includes a diverse set of items. Failing to do so limits your ability to find relevant but novel items and may hinder user engagement.
- Interpretation: Finally, it is important to interpret the serendipity scores in context and to understand what they mean in terms of user satisfaction and engagement. A high serendipity score may indicate that the recommendation system is doing a good job of suggesting surprising and unexpected items, but it is important to verify this through user feedback and other evaluation metrics.
And with this, we wrap our venture into serendipity, one of the key metrics in RecSys.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.