
A write-up on the ICML’24 paper by Zhai et al.:Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations.
Acknowledgements: This post was written by Tullie Murrell, with review and edits from Jiaqi Zhai. All figures are from the paper.
From music streaming services to e-commerce giants, recommendation systems are the invisible hand guiding our online experiences. For almost a decade, Deep Learning Recommendation Models (DLRMs) have been state-of-the-art for analyzing our every click and purchase to predict our next desires. But unlike the Transformer architectures used to power large language models (e.g. ChatGPT), DLRMs scale poorly with increased compute. That is, they stop improving when the model complexity and training time increases.
Now, inspired by the revolutionary success of language models like ChatGPT, a new approach emerges. Meta researchers are asking a radical question: what if we treated user actions – clicks, purchases, scrolls – as a language itself? This intriguing concept forms the basis of Generative Recommenders (GRs), a paradigm shift that could redefine the future of recommendations. Could this be the breakthrough that unlocks a new era of personalized experiences, or is it simply hype?
We dive into the details below, first outlining the proposed generative recommender formulation, then discussing the details of how it works and finally looking at the experimental results and conclusions.
Reimagining Recommendations: User Actions as a New Language
Modeling user actions as language isn’t as simple as feeding user interaction tokens into the input of a Transformer. The authors identify three major challenges that explain why:
-
**Feature Complexity:**Unlike the uniform and static world of text tokens, user actions are represented by a heterogeneous mix of data types including categorical, sparse features such as item and user ids and numerical, dense features such as counts and ratios.
-
Vocabulary Explosion: The vocabulary of user actions explodes into the billions, constantly evolving as new users, items, and interaction types emerge. This is significant in contrast to language, which typically has a 100k-scale static vocabulary.
-
**Computational Hunger:**GPT-3 was trained on a total of 300B tokens over a period of 1-2 months with thousands of GPUs. Even LLaMa-3, which was remarkable for the amount of data it trained on, was only trained on 15T tokens. On the other hand, an internet service with 1 billion impressions per day and at 10k sequence length generates 10T tokens per day. Recommendations can make large language model training appear small scale by contrast!
To tackle these obstacles the authors propose the GR reformulation, which models the recommendation system problems (retrieval and ranking) as sequential learning tasks. They propose a strategy to handle heterogeneous feature types using a feature sequentialization process. And finally, they propose several Transformer architectural improvements to address training and inference computation concerns.
We continue to dive into all of these contributions in more detail below.
From Predicting Words to Predicting Actions: The Two Tasks of GRs
You know how ChatGPT seems to magically anticipate the next word in a sentence? That’s the power of Transformers like GPT-3, trained to master the art of language prediction. Generative Recommenders (GRs) borrow this same concept, but instead of words, they’re predicting your next move in the digital world.
Specifically GRs learn by alternatively predicting the next content, given the user’s prior action, and the next action, given the prior content we’ve shown to the user. Using this formulation they can learn a model that GRs tackle this challenge through two distinct yet complementary approaches: ranking and retrieval.
1. The Ranking Game: Imagine you’re scrolling through your social media feed. GRs, in ranking mode, analyze your past interactions (likes, shares, comments) to predict which upcoming posts will grab your attention. They learn to differentiate between the “must-see” content and the “scroll-right-past” items, tailoring your feed to your unique tastes.
Here’s how it works: the model receives a sequence of alternating items and your actions on those items (e.g. “liked,” “shared,” “ignored”). It then alternates between predicting the next content, given the user’s prior action, and the next action, given the prior content we’ve shown to the user. Doing so is critical to enable prediction in a target-aware manner. For instance, given a piece of content being “Tamarine – Modern Vietnamese Restaurant in Palo Alto”, a target-aware formulation can extract user features based on their historical CTR/LTR/etc. on Palo Alto restaurants and Vietnamese restaurants through self-attention layers, which are arguably the most important features for CTR prediction.
At inference time the predicted action0 item can be used as a score for a set of candidate items.
2. The Retrieval Challenge: Now imagine you’re searching for a new pair of headphones. This time, GRs shift into retrieval mode, scouring the vast digital landscape to pinpoint the perfect items to present to you. They learn to associate your past actions with specific items, uncovering hidden connections and unearthing hidden gems you might have missed otherwise.
In this task, the model receives pairs of items and your corresponding actions. Its mission: predict the next item you’ll interact with, taking into account both your past behavior and the context of the current session.
By mastering both ranking and retrieval, GRs offer a powerful one-two punch for delivering highly personalized and engaging user experiences.
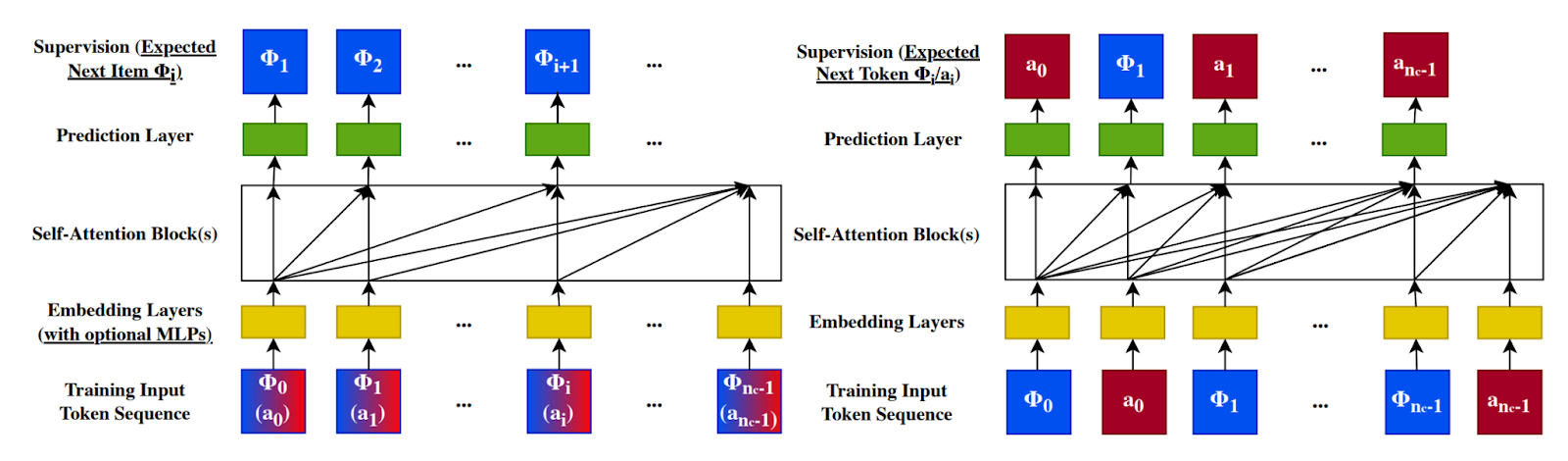 Figure shows a comparison of traditional sequential recommenders (left) and Generative Recommenders (right).
Figure shows a comparison of traditional sequential recommenders (left) and Generative Recommenders (right).
The Language of Actions: How GRs Decode Your Digital Timeline
Remember those “Life Timeline” infographics showing milestones from birth to present day? Generative Recommenders (GRs) take a similar approach, but instead of capturing major life events, they’re interested in the evolving story of your online behavior.
Here’s the key: GRs see all user features as time series – a chronological record of actions and preferences. Think of it like this:
-
Fast-Forward: Some series change rapidly, capturing the ebb and flow of your immediate interests. What items did you just like? What videos are you watching right now?
-
Slow and Steady: Other series evolve more gradually, reflecting long-term trends and shifts in taste. What creators do you consistently follow? What communities resonate with you over time?
To make sense of this intricate web of timelines, GRs cleverly merge them into one master user sequence. They prioritize the fastest-changing series as the main narrative, weaving in relevant updates from the slower-changing series at specific intervals (see figure below). This allows the model to capture both short-term fluctuations and long-term trends in your behavior.
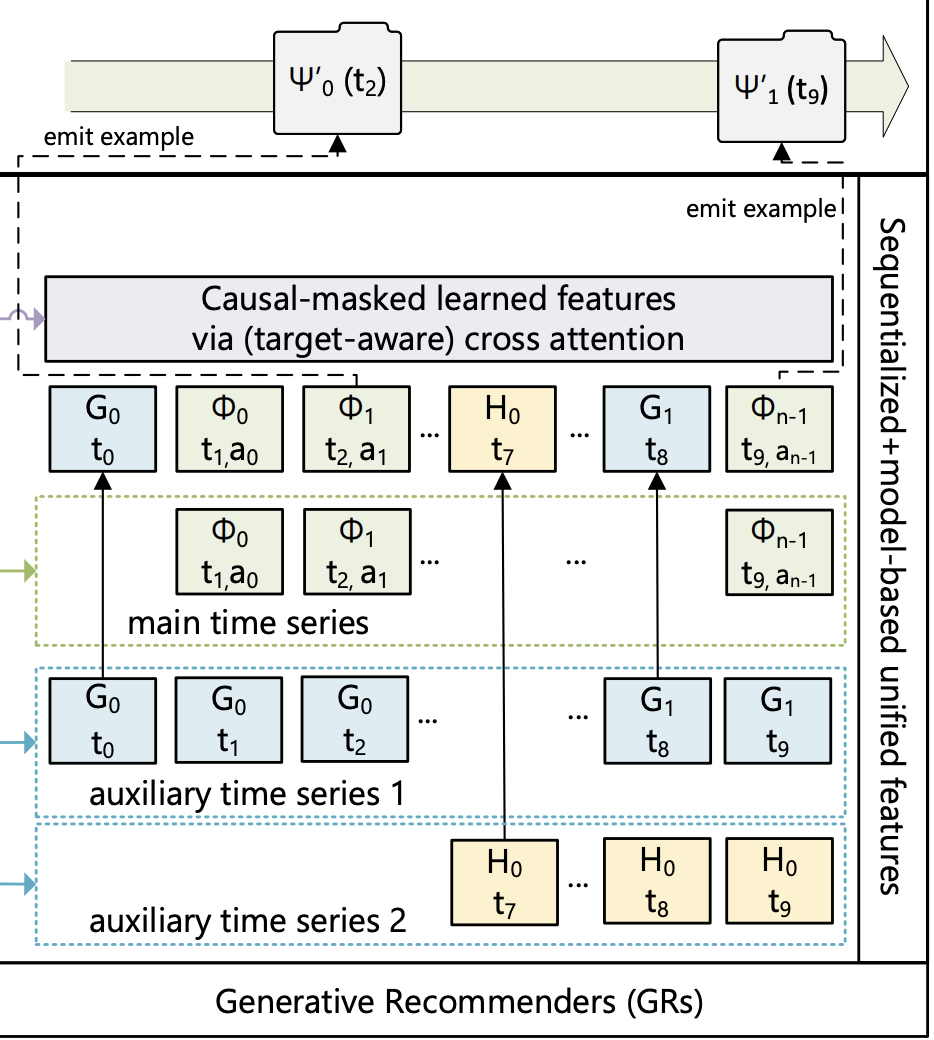 Figure shows how features can be sequentialized and applied to the model. Full notation can be found in the appendix of the paper.
Figure shows how features can be sequentialized and applied to the model. Full notation can be found in the appendix of the paper.
What about those dense numerical features we previously mentioned, like past click-through rates? GRs take a bold stance: remove them! The rationale is simple yet powerful: if the model is effectively learning from the sequentialized features, it can infer these metrics directly from your actions.
Scaling Up to the Challenge: HSTU, the Powerhouse Behind GRs
GRs need an architecture capable of handling the immense scale and complexity of real-world recommendation datasets. That’s why the authors proposed Hierarchical Sequential Transduction Unit (HSTU) – a novel encoder architecture specifically designed to power GRs at industrial scale.
To understand HSTU’s elegance, let’s first rewind to the traditional DLRM approach. These models typically involve three distinct stages:
-
**Feature Extraction:**Think of this as gathering ingredients. DLRMs retrieve the relevant “flavor profiles” – the pooled embedding representations – of various categorical features.
-
Feature Interactions: Now it’s time to mix those flavors. This stage models the complex interplay between features, often employing techniques like factorization machines.
-
Transformations of Representations: Finally, the dish is seasoned and plated. This stage refines the learned representations, frequently using techniques like Mixture of Experts (MoEs) to cater to diverse user groups.
HSTU condenses these three stages into a single, repeatable module. Each HSTU layer is comprised of three sub-layers:
-
Pointwise Projection: This layer maps input features to a shared representation space, setting the stage for meaningful interactions.
-
Spatial Aggregation: Here, the magic of capturing relationships unfolds. This layer allows information to flow between different feature representations, mimicking the “feature interaction” stage of DLRMs.
-
Pointwise Transformation: Finally, this layer refines the learned representations, adding depth and complexity to the model’s understanding.
By stacking multiple HSTU layers with residual connections, GRs achieve a balance of expressiveness and efficiency. They can process vast, dynamic vocabularies of user actions without succumbing to the computational bottlenecks that plague traditional DLRMs.
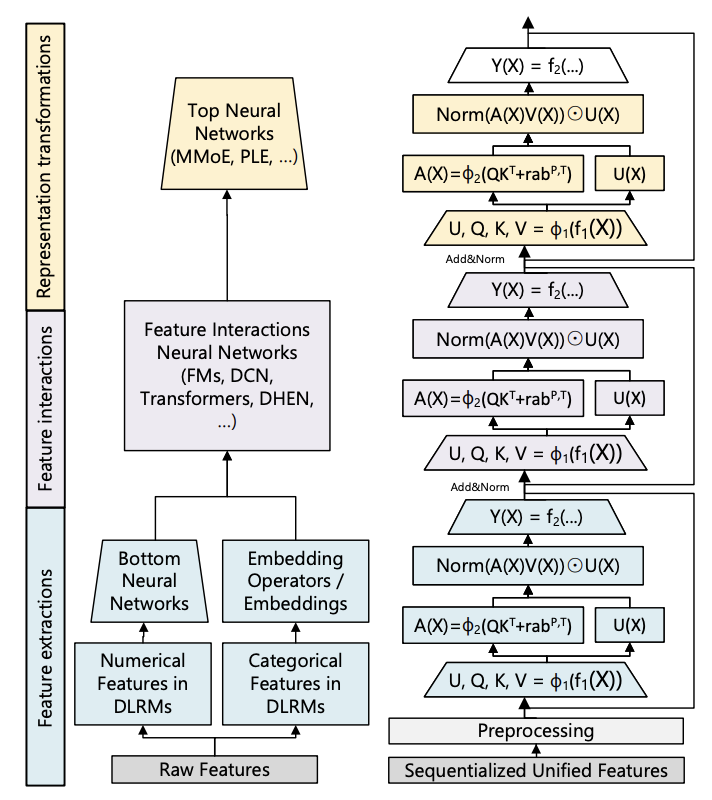 Figure shows a comparison of traditional deep-learning recommendation model architectures vs generative recommender HSTU module.
Figure shows a comparison of traditional deep-learning recommendation model architectures vs generative recommender HSTU module.
Scaling Recommendation Inference with M-FALCON
Recommending the best item from a pool of millions requires efficient search and scoring.
-
Retrieval with MIPS: GRs can utilize algorithms such as Maximum Inner Product Search (MIPS) for fast and scalable retrieval, narrowing down the initial pool of candidates to a more manageable subset.
-
Ranking with M-FALCON: To rank remaining candidates efficiently, GRs introduce M-FALCON (Microbatched-Fast Attention Leveraging Cacheable Operations). This algorithm leverages microbatching and caching techniques to process multiple candidates simultaneously. Here’s how it works:
-
Parallel Processing: M-FALCON modifies attention masks and biases, allowing it to perform the same attention operations for multiple candidates in parallel.
-
Microbatched Efficiency: Candidates are divided into smaller microbatches to leverage encoder-level caching, significantly speeding up computations.
As a result, M-FALCON enables GRs to scale model complexity linearly with the number of candidates, a critical advantage over traditional DLRMs. These changes combined make serving a 285x more complex GR model at 3x QPS!
Experimentation & Results
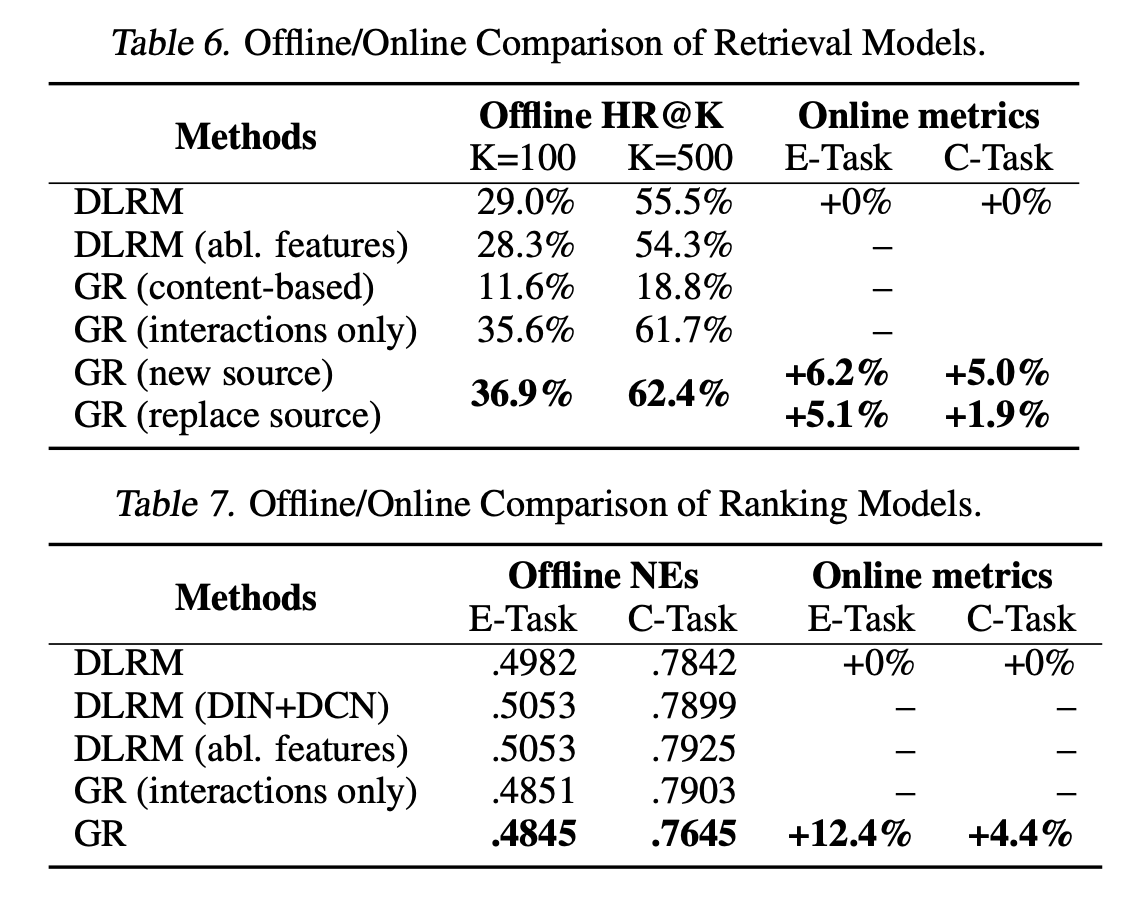
How do Generative Recommenders (GRs) actually perform in the real world? The authors evaluated GRs in both academic benchmark datasets and industrial-scale ranking use-cases at Meta.
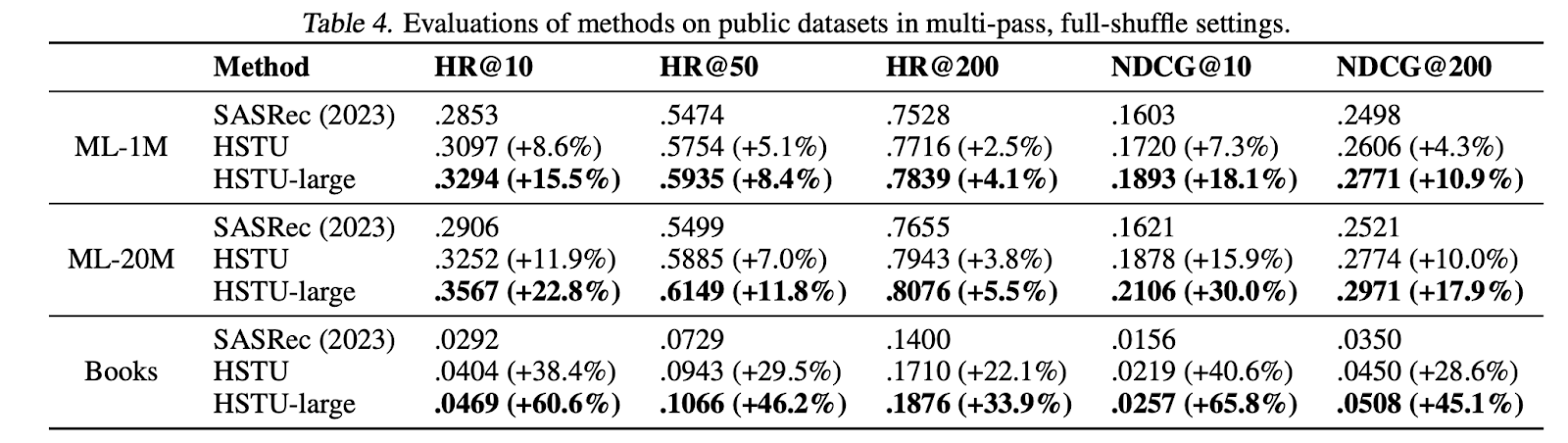
**Academic datasets:**First, they pitted GRs against the state-of-the-art SASRec model on two classic recommendation datasets: MovieLens and Amazon Reviews. Using evaluation metrics like Hit Rate@K and NDCG@K, GRs consistently outperformed SASRec, showcasing their ability to effectively learn from sequential user data for static academic datasets.
Online datasets: The real test came when GRs were deployed into production after being trained on a staggering 100 billion examples using clusters of up to 256 powerful H100 GPUs. In this environment, where performance directly impacts user experience and business outcomes, GRs delivered impressive results:
-
Ranking Supremacy: Compared to highly optimized DLRM models, GRs achieved remarkable 12.4% gains in A/B tests for the platform’s main engagement metric.
-
The Power of Combined Features: GRs achieved the best results when leveraging both interaction and content features. Interestingly, relying solely on interactions resulted in a 2.6% performance dip, while using only content features led to a significant 25.3% decrease.
Rewriting the Scaling Laws:
Perhaps the most exciting result? GRs demonstrated a clear ability to continue improving as training data and model size increased. This is a stark contrast to traditional DLRMs, which often plateau in performance despite increased resources. The authors provide compelling evidence that GRs have finally cracked the code to unlocking continuous performance gains in recommendation systems – a game-changer for the field. The future of recommendations is here, and it’s generative.
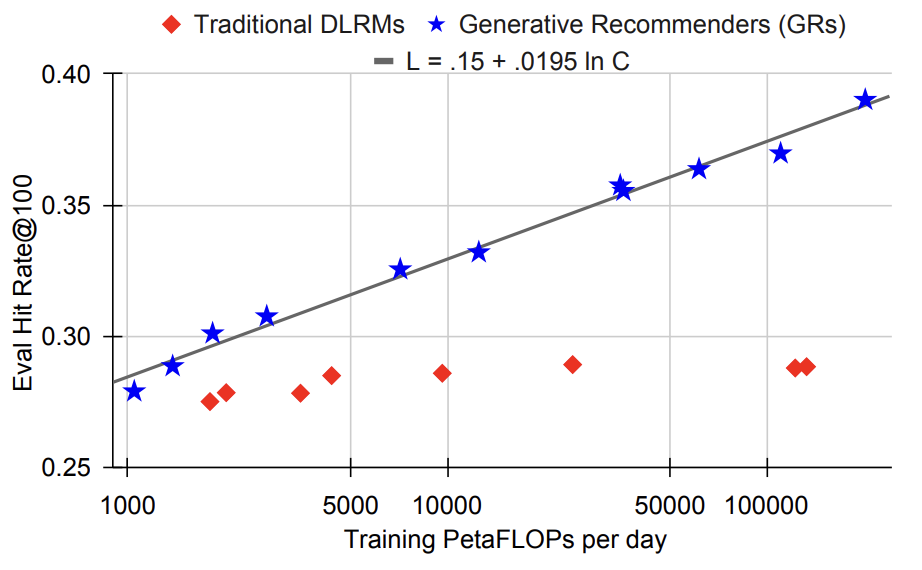 Figure shows the scalability of DLRMs vs GRs for retrieval tasks.
Figure shows the scalability of DLRMs vs GRs for retrieval tasks.
The Future of Recommendations: Actions Speak Louder (and Smarter)
The arrival of Generative Recommenders (GRs) marks a pivotal moment in the evolution of personalization. By daring to treat user actions as a language unto itself, Meta’s researchers have unlocked a powerful new paradigm with the potential to reshape the landscape of online experiences.
GRs don’t just outperform traditional DLRMs on benchmark datasets; they thrive in the real world, achieving significant gains in user engagement on a massive, industrial scale. With their innovative HSTU architecture, efficient optimization techniques, and the ability to continuously improve with more data, GRs offer a glimpse into a future where recommendations are not just accurate but truly understand and anticipate our evolving needs and desires.
This future is closer than you think. At Shaped, we’re at the forefront of this revolution, incorporating cutting-edge models like GRs into our platform as they’re released. We’re passionate about helping businesses of all sizes harness the power of personalized experiences to drive engagement, increase conversions, and, ultimately, build better interfaces for end-users.
Ready to unlock the power of GRs and take your recommendations to the next level? Get started with Shaped here.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.