
As a kid, I absolutely loved playing Pokemon. In retrospect, perhaps this love actually bordered on obsession. So when I was given my first ever GameBoy Advance on Christmas of 2005 with a copy of Pokemon Emerald, I was quite possibly the most excited child in the Southern Hemisphere for an entire week. But this joy of finally playing the game nonstop I had wanted to have for so long very quickly turned into pure frustration when I hit a particular road block within Pokemon Emerald, Granite Cave:
 Wandering around Granite Cave on Pokemon Emerald was a nightmare
Wandering around Granite Cave on Pokemon Emerald was a nightmare
For those who didn’t grow up as complete Pokemon nerds like I did, Granite Cave is an area of the game where your field of view as the character is reduced to next to nothing as you make your way through the near pitch black environment, making it near on impossible to traverse the area without some help. After giving up on this level and believing that I’d never progress any further, a buddy of mine at school told me I could obtain an ability called Flash from the nearby town. So I brought my GameBoy to school, and at recess that day he showed me how to obtain it, which totally blew my 7 year old mind. I could finally see the entire map and was able to make my way through:
 With Flash walking around the Cave was a piece of cake!
With Flash walking around the Cave was a piece of cake!
If you’re thinking what the relevance of this silly story from my childhood is, it is that I believe that embeddings have the potential to be the Flashability of modern companies, a way of illuminating the landscape beyond the limited flashlight view of traditional Data Science methods of the past.
Typically, companies utilize well-known Data Science methods to analyze segments of their business, whether it be customer data, marketing research, or even administrative tasks, in an isolated manner; meaning that they draw segregated conclusions from each individual relevant task related to data they possess. Embeddings aims to change this whole paradigm, by allowing businesses to gather insights from the collective viewpoint of all their data rather than inferences made by snapshots of singular datasets.
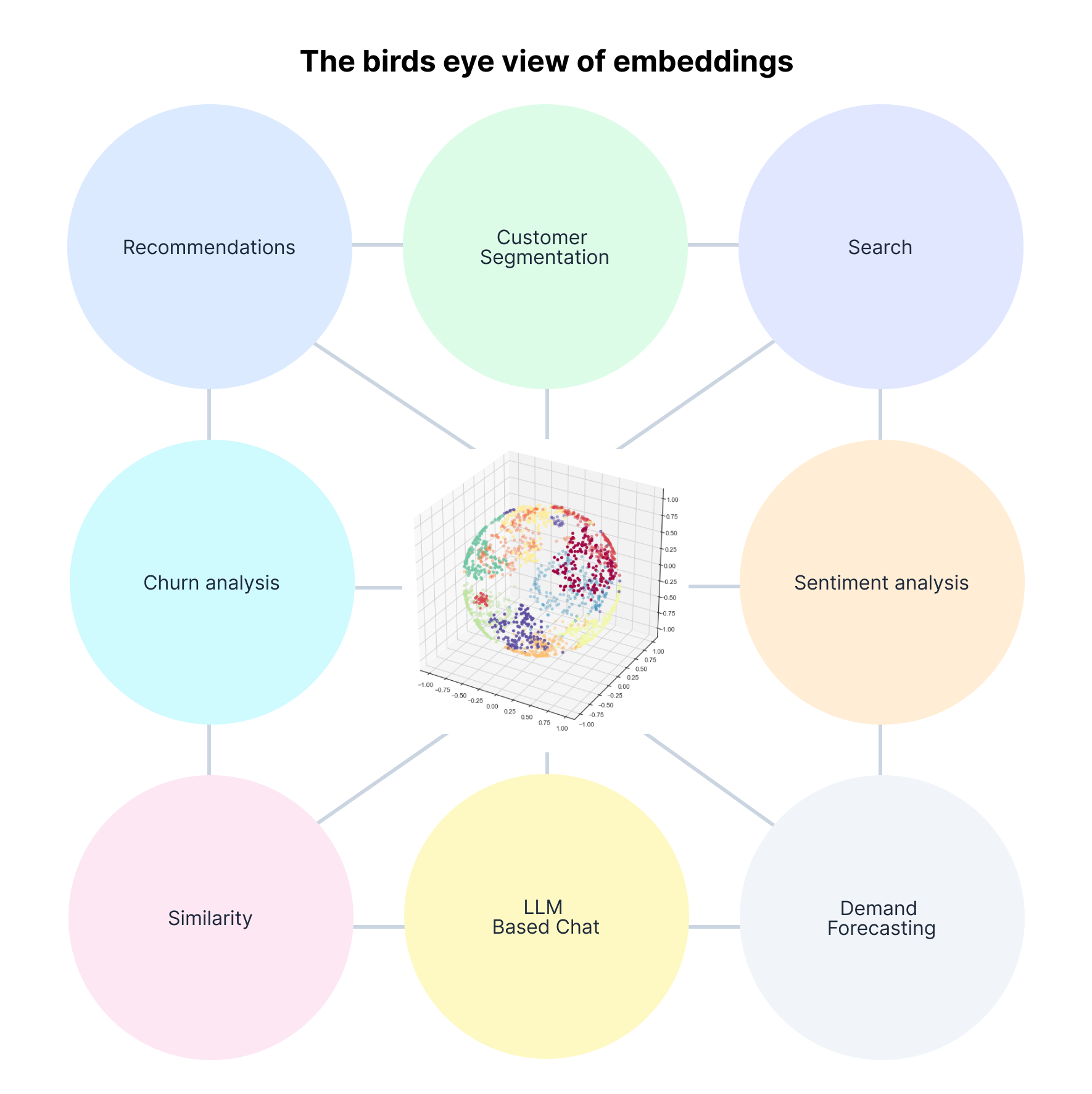 Embeddings create universal understanding of users that can power all AI systems within companies
Embeddings create universal understanding of users that can power all AI systems within companies
Embeddings allow companies to achieve this by essentially acting as a numerical translator from unstructured data types to numeric vector representations, thus unlocking the potential of any unstructured data that a business may have, which was once thought irrelevant to numerical Data Analysis and left on the cutting room floor. By being able to do this, embeddings can go a long way to achieving a more nuanced universal understanding environment that is able to handle all types of tasks relevant to data within the company.
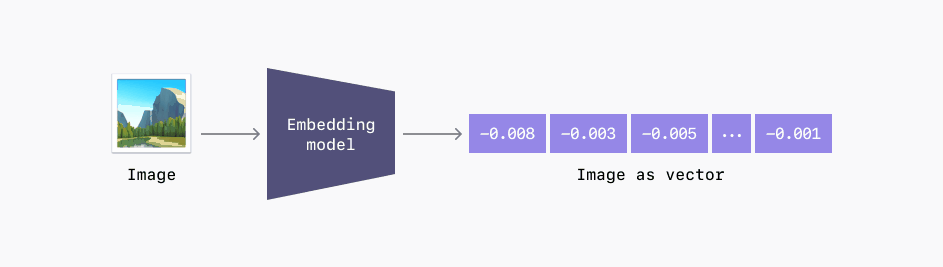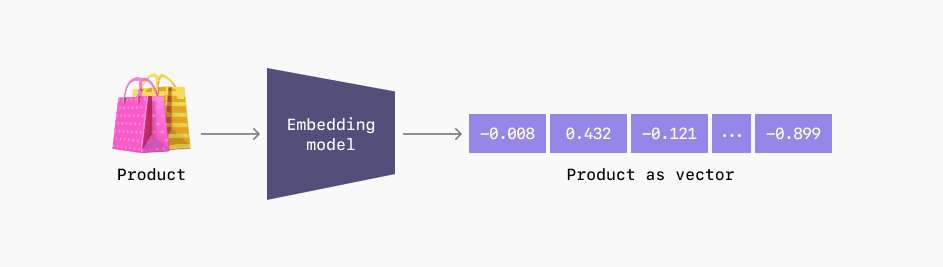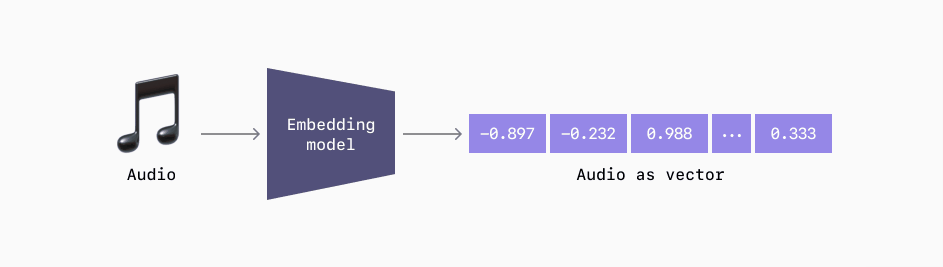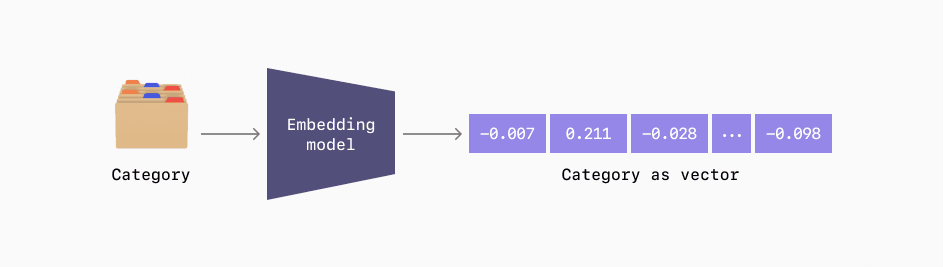 Any data type can be converted into an embedding
Any data type can be converted into an embedding
Embeddings now can give companies the ability to numerically understand data that is not even statistical in nature. Do you have metadata of customer interactions on your website? Embeddings can handle that. Do you have free form text reviews of your product by customers? Embeddings knows how to deal with language. The potential of vector embeddings when applied to any of your customer data can allow you to explore the nature of your data that was once thought impossible to analyze with any numerical rigor or conviction. In many senses, it acts as the bridge between unstructured human-enforced data and the technical powers of machine learning algorithms.
By acting as a translator from unstructured data to an appropriate vector space, embeddings can enable AI to perform nuanced, linguistically adept analyses on the entirety of a company’s data pool—essentially a ‘Zoomed Out’ view that encompasses building holistic customer personas, cohort analysis, and understanding user psychology, thus replacing simple keyword searches with a system that understands context, sentiment, and subtle differences within data points that from a traditional Data Science perspective would be perceived to be numerically similar. This in turn, allows for the creation down the line of a shared workspace for continuous, contextually aware insights that evolve from the static snapshots of the past to dynamic, universally comprehensible environments, streamlining everything within a business from marketing and research to strategy and administrative tasks into a unified, continuously updating analysis system.
This shift from traditional data science methods to harnessing embeddings really comes into its own when applying it to customer data. Companies that want to get a glimpse into the purchasing behavior of their customers have previously had to take a categorisation approach to their users; sorting and placing them into rigid categories that they identify and treat differently. Embedding powered AI can do this, but on a much more personalized scale for each customer. Rather than identifying a few key features from a user’s data, embeddings allow one to capture all the nuanced data lost through this sorting process by creating individualized ‘personas’ in much higher dimensional space that is required for this level of specificity.
Let’s consider a user of a marketplace. Mia is a 30 year old female graphic designer with an annual income of $90000 who lives in Los Angeles. Recent data detailing her purchase history shows that she has a particular taste for both unique modern and retro clothing, and is looking to buy some new jeans that reflect her meshes of style. She has been reading a lot of reviews on different brands, but is still unsure of what she wants. Using typical data science strategies and limited feature extraction, a user such as this could be automatically placed in a category such as an ‘Early_Adopter’ user profile, showing them newer items that may not be as necessarily trending in terms of overall popularity and purchase count. However, if we use embeddings and all of the relevant unstructured data relevant to Mia, we can construct a much more thorough and nuanced analysis of the intent, motivation and conditions behind her purchasing behavior. This would allow us to see that semantically, we can recommend a series of items that capture her blend between two distinct styles.
 Example embedding of a product. Note: Users can be embeddings as well.
Example embedding of a product. Note: Users can be embeddings as well.
This transition from basic customer segmentation to user level behavior synopsis creation also solves a few other problems that occur with using typical structured Data Science to understand customers and users. By bucketing users into discrete categories through the analysis of a few features within their data, these traditional methods are highly prone to stereotyping users into groups they may not necessarily belong to. For example, traditional methods may incorrectly categorize a young female user by initially advertising them solely beauty products, despite them not being interested in anything of the sort. Essentially, these segmentation methods are not able to capture the complexity and dimensionality of consumer behavior, and consequently pigeonhole users based on demographics instead of their unique preferences and behavior patterns.
According to tech research firm Gartner, unstructured data now accounts for an estimated 80-90 percent of all data stored online. Essentially, the prominence of data that cannot be neatly presented in an Excel spreadsheet in today’s world is overwhelming. Most companies also possess this imbalance between structured and unstructured data, with the majority of data such as company emails, customer feedback, audio and internal documents just to name a few, not being used by their modern machine learning frameworks.
Just think of the potential insights that could be made available to companies if they were able to perform similarly rigorous analysis on their unstructured data that is nearly 10 times as common within their walls as their numeric data. Embeddings could find insights within language used in a document in order to find the consistency between what is being written and the numerical validity of the associated data analysis being performed. This interconnectedness between tasks of all domains across a company will allow businesses in the future simultaneously obtain high level sentimental conclusions on their data in conjunction with base level traditional Data Science predictions.
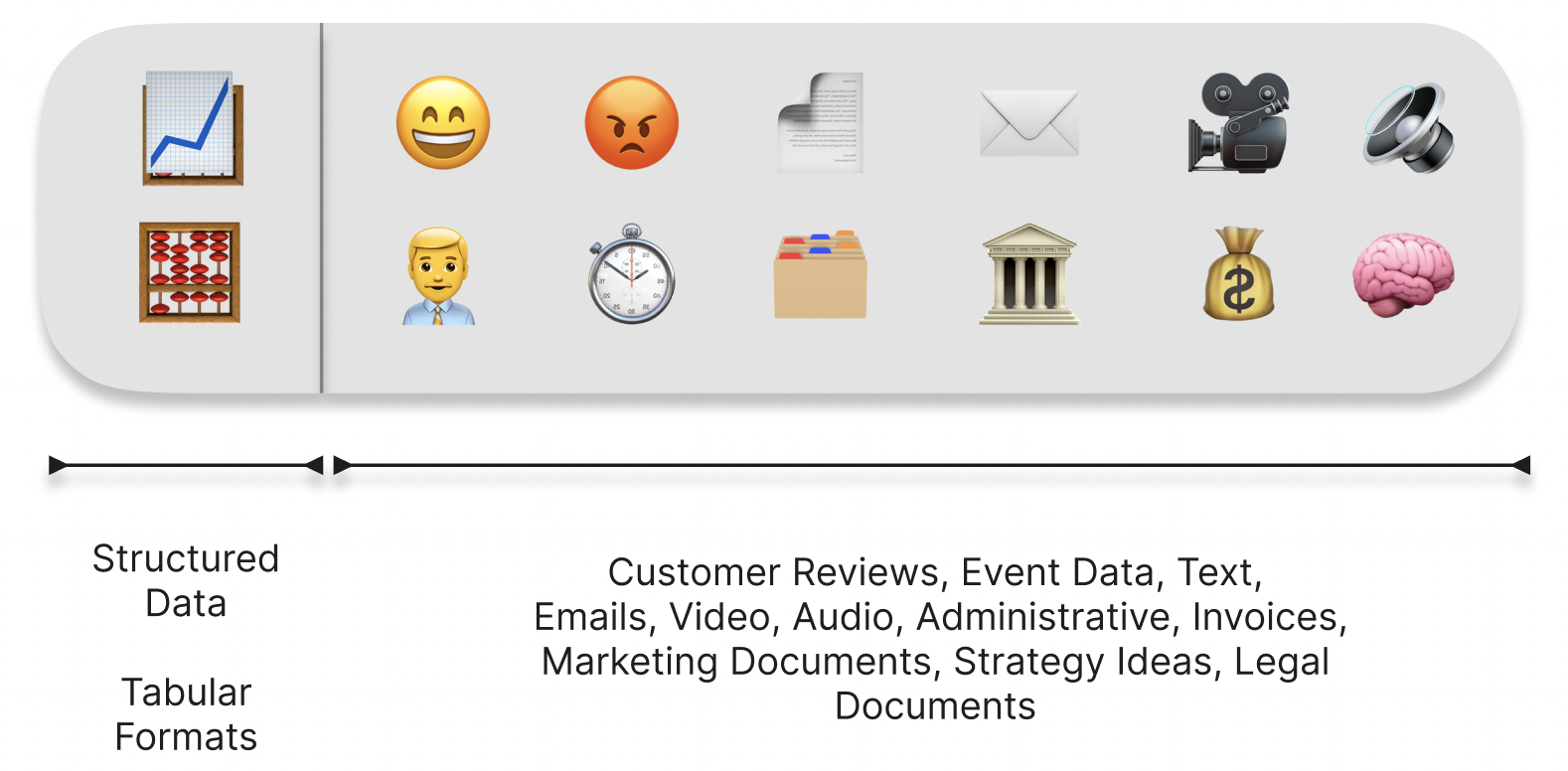 With embeddings you can use all of your data to power AI systems
With embeddings you can use all of your data to power AI systems
With access to the benefits of modern AI in tandem with the conversion of unstructured data to a format that machine learning models can understand, the true power of this shift lies in the ability to ask more powerful and revealing questions concerning the nature of your data. Embedding your unstructured data still allows you to preserve the original intricate relationships between data points, allowing businesses to delve deeper into patterns, correlations, and outliers that might otherwise remain elusive. Through embeddings, businesses can inquire not just about individual data points but also about the contextual associations, similarities, and disparities between them. This capability grants the freedom to explore the underlying nature of the data, uncover hidden insights, and derive actionable intelligence. As a result, organizations can formulate more incisive queries, leading to richer analyses, smarter decision-making, and a profound understanding of their data landscape.
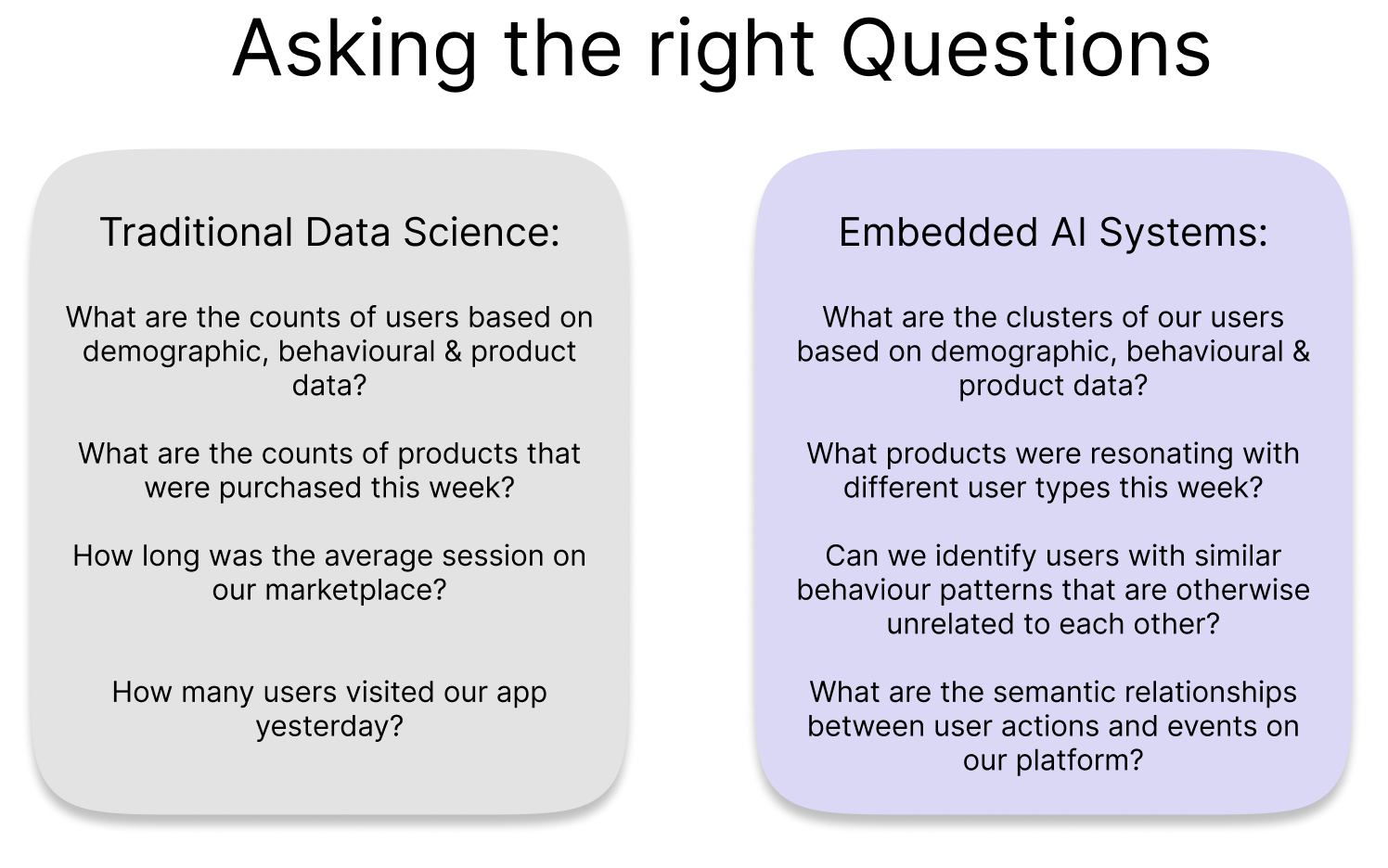 Embeddings allow you to ask and answer nuanced questions
Embeddings allow you to ask and answer nuanced questions
The advancement of embeddings and their use in tandem with machine learning represent a new frontier in data analysis for businesses, offering an integrated and nuanced perspective of data that goes far beyond the limitations of traditional methods. By being able to convert unstructured data into numerically meaningful formats, embeddings allow companies to construct encompassing narratives for their users, items and events they keep track of, revealing insights that were previously inaccessible. Ultimately, the adoption of embeddings within companies signifies a paradigm shift towards a more contextual and intuitive approach to data science, one that promises to unlock a deeper understanding of the data landscapes that businesses now have to navigate. Embracing embeddings is not just about taking on a new technology; it’s about redefining the way we perceive and interact with data. Say goodbye to rigid, isolated analysis of your datasets, it’s time to start creating stories that can explore your data’s full potential.
 Embeddings does what traditional DS can not
Embeddings does what traditional DS can not
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.