Ranking and recommendations are crucial for the growth of any successful internet company. Think about products like TikTok, Spotify or Instagram and you’ll quickly realize how important ranking is for both user experience and product engagement. These companies understand this extremely well — they invest huge amounts into their ranking teams and are constantly improving their models with state-of-the-art research. For the most part though, it’s the volume and quality of data that makes their rankings algorithms so addictive. So how can you get the most of your data so that your ranking algorithms are as good as big tech? One thing that can help is data-centric AI!
What is data-centric AI?
Data centric AI is a paradigm for machine-learning where you focus on engineering the data rather than the models that use that data. The idea is that machine-learning models have become general enough that most performance improvements can be made by focusing on the data while using off-the-shelf models. Rather than spending time on algorithm design and custom model architectures, a data centric AI workflow involves quickly iterating on different datasets and data preprocessing that can make your model perform better.
 Data-centric AI is all about iterating on your training datawhile keeping your model constant (fromSnorkel.ai).
Data-centric AI is all about iterating on your training datawhile keeping your model constant (fromSnorkel.ai).
In the industry, several companies have positioned themselves around data centric AI. Andrew Ng -a famous AI researcher that started the data-centric AI movement - created Landing AI, a company that helps manufacturers improve visual inspection with a focus on making the most out of small amounts of data. Snorkel.ai is another data-centric AI company that allows users to programmatically build and manage train datasets.
 Several recent AI research breakthroughs have also come from a data-centric AI approach. The main insight behindMinerva, was to use a large dataset made of webpages with mathematical content and scientific papers using thePaLMmodel architecture.
Several recent AI research breakthroughs have also come from a data-centric AI approach. The main insight behindMinerva, was to use a large dataset made of webpages with mathematical content and scientific papers using thePaLMmodel architecture.
Although the data-centric AI terminology is new, the best data practitioners have been doing it this way for years. What’s new is that it’s becoming more of a discipline, there are more tools being built around getting the most from your data, and there are better plug-and-play models (e.g. from HuggingFace) that allow you to focus on the data.
Data-centric AI for ranking
A data-centric AI workflow is particularly important for ranking and recommendations. Recommendation datasets typically contain inhomogenous data types, including: numerical data like product price, categorical data like music genre, language data like product description. These require work to be cleaned and preprocessed in a way that your model can consume. Furthermore, recommendation data tends to be very sparse, and getting the most from your interaction labels is crucial.
So how can you best handle the inhomogenous and sparse data that is inherent to recommendation problems? Below we discuss several data-centric AI tips you can use to improve the performance of your recommendation system without having to change your model.
1. Data sources
One of the best ways get the most from your data is finding or acquiring more of it. The more user interaction events and contextual features you can experiment with, the better. To find these, think about all the different data sources you can get relevant data from. Is it all in one place (e.g. your data warehouse)? Or is it spread out amongst your applications (e.g. in Amplitude or Segment)? Do you even store interaction data? If not you may have to start logging it before getting started.
For user and item contextual feature data, consider all the areas that you store entity metadata. For users, look for demographic, interest or related metadata (e.g. when they created an account). For your items (i.e. the entity being ranked), consider contextual data such as captions, categories, images, author or price.
For interactions, recommendation models typically require you to define positive and negative events that define your objective. For positive interactions look for any auxiliary labels that correspond to your final business goal. If your business goal is to improve engagement, make sure you have like, comment, or time-spent labels. If it’s conversions, ensure you have events for purchases, clicks, add-to-carts. You’ll also want to retrieve negative labels from your data sources. A negative label could be an impression, swipe left, or dislike. The more of these labels that can feed into your model, the more understanding it has of what’s going to be the best recommendation for your users.
Once you’ve identified where the data sources (including user, item and interaction data), you’ll need to move it to a place where it can be fed into your model. Tools like Fivetran can help with this if you want to skip building the data pipeline and connectors yourself.
2. Finding data quality issues
Production data used for machine-learning is likely have data quality issues that need to be addressed. You may have NULL/NaN values in certain fields where a user didn’t enter data, you may have new categories that have only been added recently and can’t be backfilled, timestamps might come from different timezones etc… You may also have a lot of imbalance within your dataset, e.g. too few interactions for a particular category.
The main tip for this section is to ensure you’re exploring your data to surface these issues. This can be done with descriptive statistics and visual plots. We recommend looking at:
- Plots of the interaction event frequency for each contextual feature or label. This will surface imbalances or abnormalities within your data.
- Plots of frequency of each contextual feature over time. This can surface data quality issues that happen over a time specific period. For example, looking at the frequency an item is being interacted with over time may show data gaps or timezone issues.
- Your target label’s mean and variance over time.
- Random samples of the data. This is always worth starting with as a sanity check of what the contextual features contain. E.g. does the language field correspond to the language in the description.
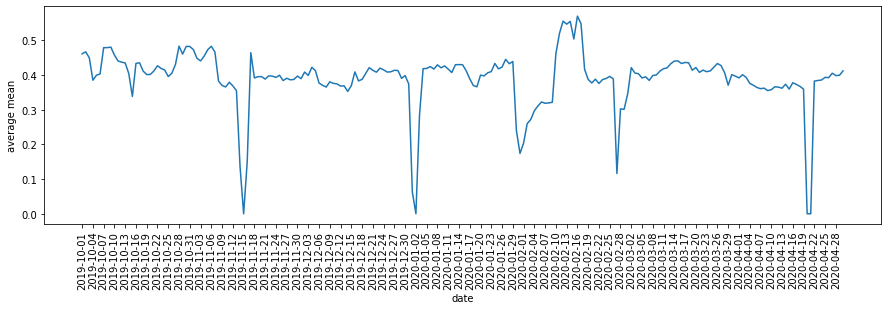 Some suspicious sporadic target changes that may need to be investigated (Fromhttps://recsys.acm.org/recsys20/tutorials).
Some suspicious sporadic target changes that may need to be investigated (Fromhttps://recsys.acm.org/recsys20/tutorials).
3. Data cleaning
Following on from our last section, once you’ve identified problems with your data, you’ll want to fix them before feeding the data into your model. Several suggestions include:
- Handling missing values with category imputation (e.g. setting them to a Nan column) or numerical imputation (e.g. setting it to the mean, median or prediction of another model). Also consider removing the data but be careful not to introduce bias.
- Combine categories that are similar and have low event counts.
- Convert timestamps to the same timezone.
- Understand and filter out spurious correlations i.e. when a non-causal attribute correlates with the label.
4. Feature encodings
To make the most of your data, encoding the features in different business centric ways can be beneficial. For example:
- Creating interaction features from your categories by combining data that has a clear learnable pattern.
- Target encoding - by combining the mean of the target for each category with the input dataset.
- Count encoding - combining the frequency of a category with the input dataset. This allows the model to group categories based on their frequency.
- Bin categories into semantically relevant ways. For example binning timestamps into weekdays and weekends.
- Computing cyclic features from different time periods.
5. Continuous Retraining
Retraining your production recommendation models on recent data periodically is the final data-centric AI improvement we’ll discuss. It helps avoid data drift that appears over time and improve your overall test performance. How often you retrain depends on how much data drift your dataset generates, e.g. a media platform may want to retrain every day to capture recent trends of the day. If you want to get complex — a dynamic retraining scheme can be used to retrain your model as drift is detected.
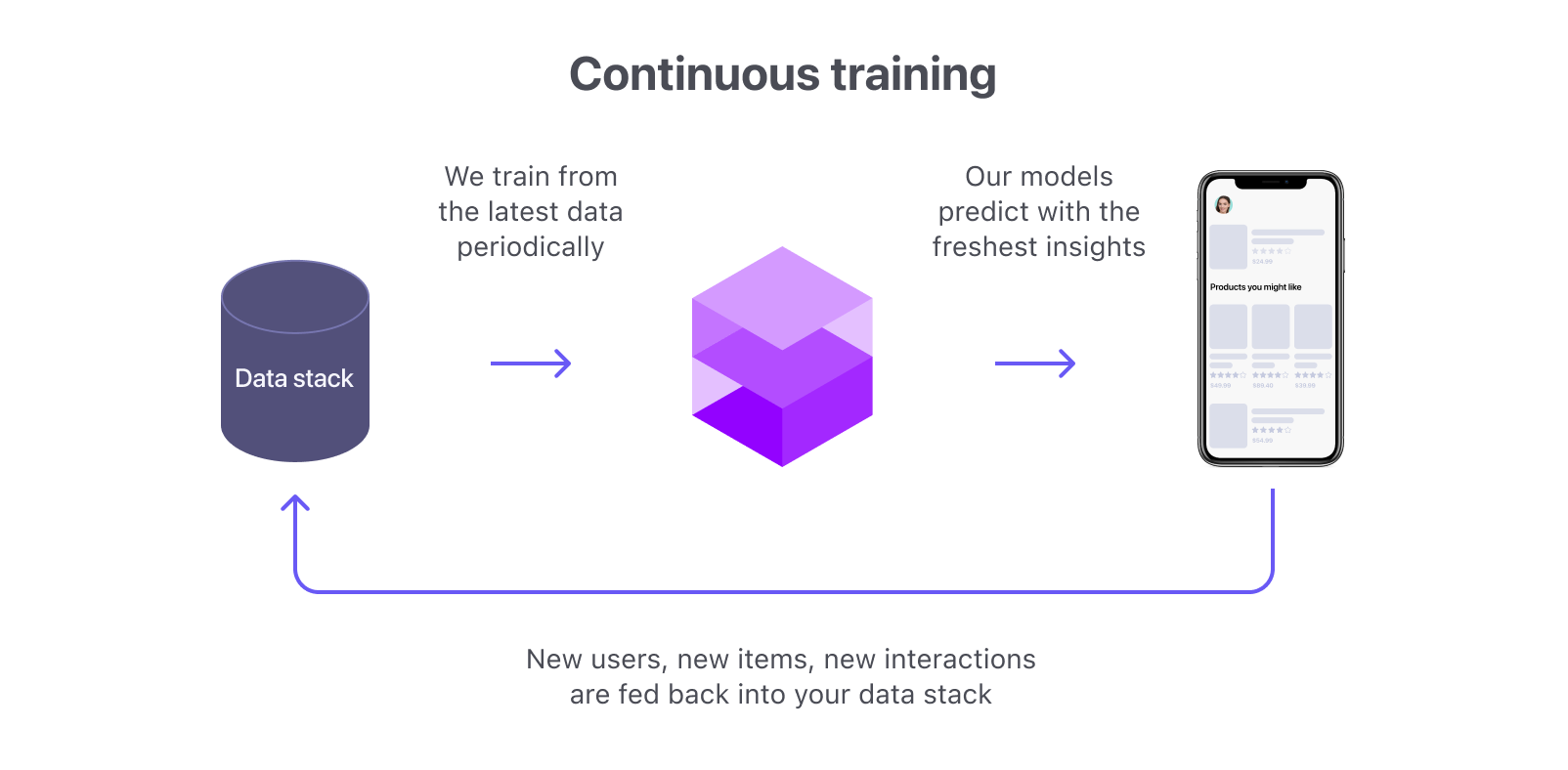 Fromdocs.shaped.ai.
Fromdocs.shaped.ai.
Conclusion
We’ve discussed several tips and techniques that align with the data-centric AI paradigm. The best thing about them is that they all work without changing the model you have! In the future we’ll discuss some more advanced techniques such as data distillation (i.e. finding a smaller dataset of important samples that will impact your performance the most), data augmentation, synthetic data generation and semi-supervised or self-supervised learning.
If you’re interested in helping build data-centric AI tools for production machine-learning, recommendations and ranking, please reach out to us at hello@shaped.ai.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.